C++类型
C++中,对象(变量)的类型通常有两种:
变量和对象
变量
变量是一个有名字的,可供程序操作的存储空间。C++ 中的每个变量都有数据类型,数据类型决定着变量所占内存空间的大小和布局方式,该空间能存储的值的范围,以及变量能够参数的运算。对于C++ 程序员来说,变量和对象一般可以互用。
对象
什么是对象,具有某种数据类型的内存空间,并不区分是复合类型还是内置类型,也不区分是否有名字和是否只读。
变量定义
一条定义语句由一个基本数据类型和紧随其后的一个或者多个声明符组成。每个声明符声明了一个变量并且指定该变量为与基本数据类型有关的某种类型。
基本变量的声明语句由数据类型和变量名组成,声明符就是变量名。而复合类型的声明语句中声明符除了变量名,还会有类型修饰符,如*,&和[]等等。比如引用的声明语句中将声明符写成&d的形式,其中d是声明的变量名,&是类型修饰符。指针是另外一种复合类型,通常将声明符写成*d的形式,其中d是变量名,*是类型修饰符。1
2
3int a = 3;
int &b = a;
int *p = &a;
在指针操作中,其中操作符*称为解引用,操作符&称为取地址符。
复合类型的定义
变量的定义包含一个基本数据类型和一组声明符。在一条定义语句中,虽然基本数据类型只有一个,但是声明符的形式却可以不同,也就是一条定义语句可能定义处不同类型的变量:1
int i = 1024, *p = &i, &r = i;
在定义语句中,类型修饰符*和&仅仅修饰紧随其后的变量。关于引用和指针的声明,一般有两种写法:
-
将修饰符和变量名写在一起,即:
1
int *p1, *p2;
-
把修饰符和类型名写在一块,即:
1
2int* p1;
int* p2;
这两种方法都对,C++ primer采用第一种。
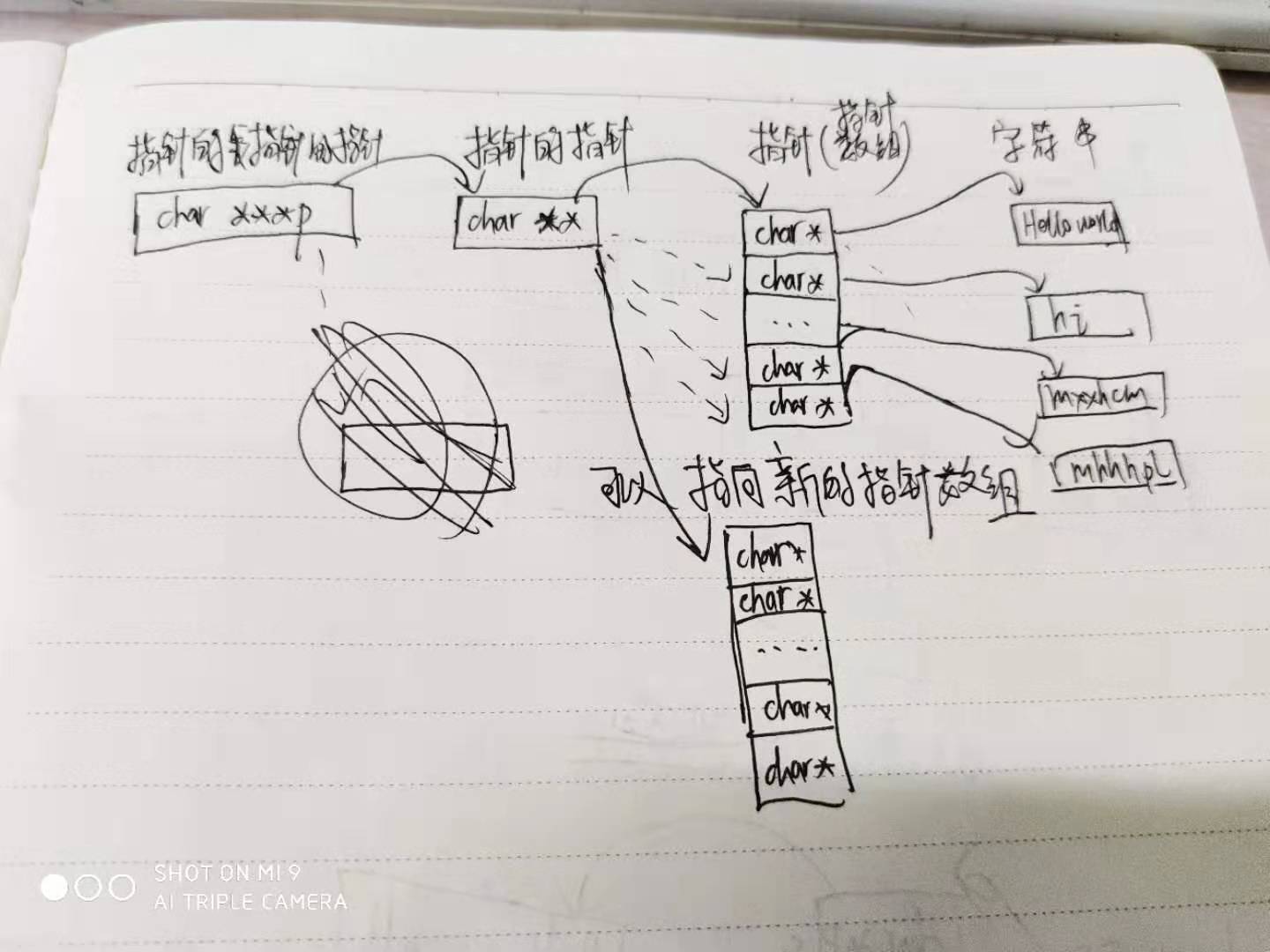
指向指针的指针
声明符中修饰符的个数没限制,可以写很多个。
1 | int ival = 1024; |
指针的引用
引用不是对象,所以指针不能指向引用。但是指针是对象,所以有指针的引用。复杂的指针或者引用的声明语句,从右往左读。
1 | int i = 42; |
变量初始化
初始化是在变量创建时给一个特定的值,而赋值是把对象的当前值擦除,使用一个新值代替。
默认初始化
当变量没有指定初值,使用默认初始化的方式进行初始化。默认值由变量类型和变量位置决定。
对于内置类型的变量,如果没有显式初始化,它的位置由定义的位置决定。函数内部的内置类型不会被初始化,定义于任何函数外部的内置类型被初始化为0。未初始化的变量的值是未定义的。
对于自定义的类型来说,每个类决定初始化对象的方式,而且是否允许不经过初始化就定义对象也由自己决定。如果类允许这种行为,由类决定对象的初始值是什么;如果类要求每个对象显示初始化,在创建类对象没有进行明确的初始化操作时,会引发错误。
声明和定义的区别
- 声明需要给出变量的类型和名字,但是不需要申请存储空间。
- 只进行声明的话使用
extern关键字,不要显式的初始化变量。包含了显式初始化的声明就变成了定义。 - 变量只能定义一次,但是可以声明多次。可以方便的在多个文件中使用同一个变量。
参考文献
1.《C++ Primer第五版》