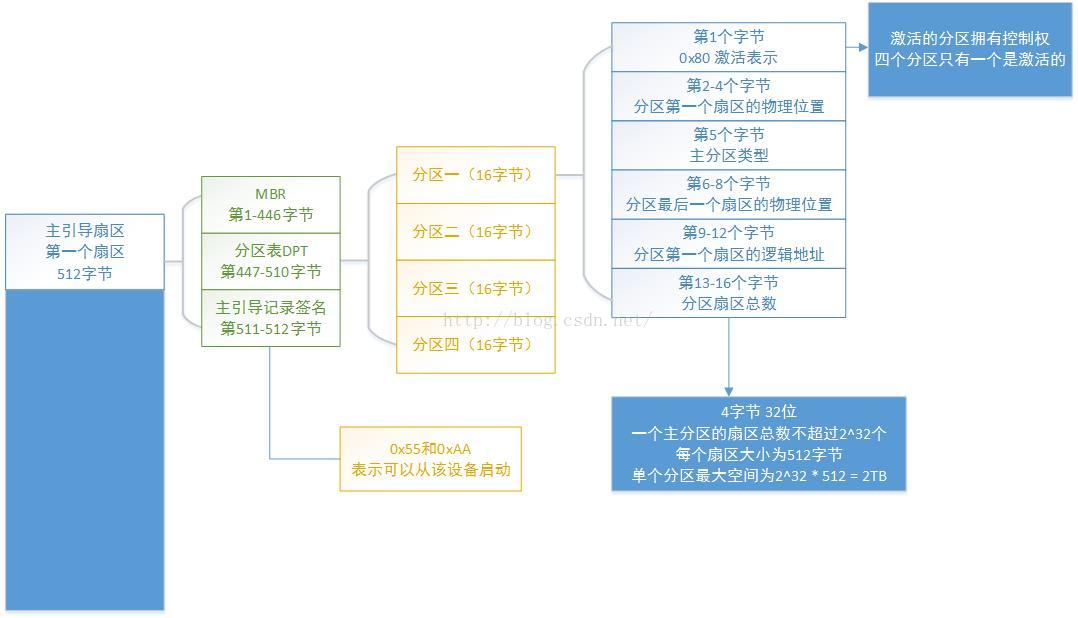
原理
Policy iteration有两种方式实现,一种是使用两个数组,一个保存原来的值,一个用来进行更新,这种方法是雅克比方法,或者叫同步的方法,因为他可以并行的进行。
In-place的方法是高斯赛德尔方法。就是用来解方程组的迭代法。
Dynamic Programming
DP指的是给定环境的模型,通常是一个MDP,计算智能体最优策略的一类算法。经典的DP算法应用场景有限,因为它需要环境的模型,计算量很高,但是DP的思路是很重要的。许多其他的算法都是在尽量减少计算量和对环境信息情况,尽可能获得和DP接近的性能。
通常我们假定环境是一个有限(finite)的MDP,也就是state, action, reward都是有限的。尽管DP可以应用于连续(continuous)的state和action space,但是只能应用在几个特殊的场景上。一个常见的做法是将连续state和action quantize(量化),然后使用有限MDP。
DP关键在于使用value function寻找好的policy,在找到了满足Bellman optimal equation的optimal value function之后,可以找到optimal policy,参见第三章推导:
Bellman optimal equation:
\begin{align*}
v_{*}(s) &= max_a\mathbb{E}\left[R_{t+1}+\gamma v_{*}(S_{t+1})|S_t=s,A_t=a\right] \\
&= max_a \sum_{s’,r} p(s’,r|s,a){*}\left[r+\gamma v_{*}(s’)\right] \tag{1}
\end{align*}
\begin{align*}
q_{*}(s,a) &= \mathbb{E}\left[R_{t+1}+\gamma max_{a’}q_{*}(S_{t+1},a’)|S_t=s,A_t = a\right]\\
&= \sum_{s’,r} p(s’,r|s,a) \left[r + \gamma max_a q_{*}(s’,a’)\right] \tag{2}
\end{align*}
Policy Evaluation(Prediction)
给定一个policy,计算state value function的过程叫做policy evaluation或者prediction problem。
根据$v(s)$和它的后继状态$v(s’)$之间的关系:
\begin{align*}
v_{\pi}(s) &= \mathbb{E}_{\pi}[G_t|S_t = s]\\
&= \mathbb{E}_{\pi}\left[R_{t+1}+\gamma G_{t+1}|S_t = s\right]\\
&= \sum_a \pi(a|s)\sum_{s’}\sum_rp(s’,r|s,a) \left[r + \gamma \mathbb{E}_{\pi}\left[G_{t+1}|S_{t+1}=s’\right]\right] \tag{3}\\
&= \sum_a \pi(a|s)\sum_{s’,r}p(s’,r|s,a) \left[r + \gamma v_{\pi}(s’) \right] \tag{4}\\
\end{align*}
只要$\gamma \lt 1$或者存在terminal state,那么$v_{\pi}$的必然存在且唯一。这个我觉得是迭代法解方程的条件。数值分析上有证明。
如果环境的转换概率$p$是已知的,可以列出方程组,直接求解出每个状态$s$的$v(s)$。这里采用迭代法求解,随机初始化$v_0$,使用式子$(4)$进行更新:
\begin{align*}
v_{k+1}(s) &= \mathbb{E}\left[R_{t+1} + \gamma v_k(S_{t+1})\ S_t=s\right]\\
&= \sum_a \pi(a|s)\sum_{s’,r}p(s’,r|s,a) \left[r + \gamma v_k(s’) \right] \tag{5}
\end{align*}
直到$v_k=v_{\pi}$到达fixed point,Bellman equation满足这个条件。当$k\rightarrow \infty$时收敛到$v_{\pi}$。这个算法叫做iterative policy evaluation。
在每一次$v_k$到$v_{k+1}$的迭代过程中,所有的$v(s)$都会被更新,$s$的旧值被后继状态$s’$的旧值加上reward替换,正如公式$(5)$中体现的那样。这个目标值被称为expected update,因为它是基于所有$s’$的期望计算出来的(利用环境的模型),而不是通过对$s’$采样计算的。
在实现iterative policy evaluation的时候,每一次迭代,都需要重新计算所有$s$的值。这里有一个问题,就是你在每次更新$s$的时候,使用的$s’$如果在本次迭代过程中已经被更新过了,那么是使用更新过的$s’$,还是使用没有更新的$s’$,这就和迭代法中的雅克比迭代以及高斯赛德尔迭代很像,如果使用更新后的$s’$,这里我们叫它in-place的算法,否则就不是。具体那种方法收敛的快,还是要看应用场景的,并不是in-place的就一定收敛的快,这是在数值分析上学到的。
下面给出in-place版本的iterative policy evation算法伪代码。
iterative policy evation 算法
输入需要evaluation的policy $\pi$
给出算法的参数:阈值$\theta\gt 0$,当两次更新的差值小于这个阈值的时候,就停止迭代,随机初始化$V(s),\forall s\in S^{+}$,除了$V(terminal) = 0$。
Loop
$\qquad \delta \leftarrow 0$
$\qquad$ for each $s\in S$
$\qquad\qquad v\leftarrow V(s)$ (保存迭代之前的$V(s)$)
$\qquad\qquad V(s)\leftarrow\sum_a \pi(a|s)\sum_{s’,r}p(s’,r|s,a) \left[r + \gamma v_k(s’) \right] $
$\qquad\qquad \nabla \leftarrow max(\delta,|v-V(s)|)$
$\qquad$end for
until $\delta \lt \theta$
Policy Improvement
为什么要进行policy evaluation,或者说为什么要计算value function?
其中一个原因是为了找到更好的policy。假设我们已经知道了一个deterministic的策略$\pi$,但是在其中一些状态,我们想要知道是不是有更好的action选择,如$a\neq \pi(s)$的时候,是不是这个改变后的策略会更好。好该怎么取评价,这个时候就可以使用值函数进行评价了,在某个状态,我们选择$a \neq \pi(s)$,在其余状态,依然遵循策略$\pi$。用公式表示为:
\begin{align*}
q_{\pi}(s,a) &= \mathbb{E}\left[R_{t+1}+\gamma v_{\pi}(S_{t+1})|S_t=s,A_t = a\right]\\
&=\sum_{s’,r}p(s’,r|s,a)\left[r+\gamma v_{\pi}(s’)\right] \tag{6}
\end{align*}
那么,这个值是是比$v(s)$要大还是要小呢?如果比$v(s)$要大,那么这个新的策略就比$\pi$要好。
用$\pi$和$\pi’$表示任意一对满足下式的deterministic policy:
$$q_{\pi}(s,\pi’(s)) \ge v_{\pi}(s) \tag{7}$$
那么$\pi’$至少和$\pi$一样好。可以证明,任意满足$(7)$的$s$都满足下式:
$$v_{\pi’}(s) \ge v_{\pi}(s) \tag{8}$$
对于我们提到的$\pi$和$\pi’$来说,除了在状态$s$处,$v_{\pi’}(s) = a \neq v_{\pi}(s)$,在其他状态处$\pi$和$\pi’$是一样的,都有$q_{\pi}(s,\pi’(s)) = v_{\pi}(s)$。而在状态$s$处,如果$q_{\pi}(s,a) \gt v_{\pi}(s)$,注意这里$a=\pi’(s)$,那么$\pi’$一定比$\pi$好。
证明:
\begin{align*}
v_{\pi}(s) &\le q_{\pi}(s,\pi’(s))\\
& = \mathbb{E}\left[R_{t+1} + \gamma v_{\pi}(S_{t+1})|S_t = s, A_t = \pi’(s) \right]\\
& = \mathbb{E}_{\pi’}\left[R_{t+1} + \gamma v_{\pi}(S_{t+1})|S_t = s \right]\\
& \le \mathbb{E}_{\pi’}\left[R_{t+1} + \gamma q_{\pi}(S_{t+1},\pi’(S_{t+1}))|S_t = s \right]\\
& = \mathbb{E}_{\pi’}\left[ R_{t+1} + \gamma \mathbb{E}_{\pi’}\left[R_{t+2} +\gamma v_{\pi}(S_{t+2})|S_{t+1}, A_{t+1}=\pi’(S_{t+1})|S_t = s \right]\right]\\
& = \mathbb{E}_{\pi’}\left[ R_{t+1} + \gamma R_{t+2} +\gamma^2 v_{\pi}(S_{t+2})|S_t = s \right]\\
& \le \mathbb{E}_{\pi’}\left[ R_{t+1} + \gamma R_{t+2} +\gamma^2 R_{t+3} +\gamma^3 v_{\pi}(S_{t+3})|S_t = s \right]\\
& \le \mathbb{E}_{\pi’}\left[ R_{t+1} + \gamma R_{t+2} +\gamma^2 R_{t+3} +\gamma^3 R_{t+4} + \cdots |S_t = s \right]\\
&=v_{\pi’}(s)
\end{align*}
所以,在计算出一个policy的value function的时候,很容易我们就直到某个状态$s$处的变化是好还是坏。扩展到所有状态和所有action的时候,在每个state,根据$q_{\pi}(s,a)$选择处最好的action,这样就得到了一个greedy策略$\pi’$,给出如下定义:
\begin{align*}
\pi’(s’) &= argmax_{a} q_{\pi}(s,a)\\
& = argmax_{a} \mathbb{E}\left[R_{t+1} + \gamma v_{\pi}(S_{t+1} |S_t=a,A_t=a)\right] \tag{9}\\
& = argmax_{a} \sum_{s’,r}p(s’,r|s,a)\left[r+v_{\pi}(s’) \right]
\end{align*}
可以看出来,该策略的定义一定满足式子$(7)$,所以$\pi’$比$\pi$要好或者相等,这就叫做policy improvement。当$\pi’$和$\pi$相等时,,根据式子$(9)$我们有:
\begin{align*}
v_{\pi’}(s’)& = max_{a} \mathbb{E}\left[R_{t+1} + \gamma v_{\pi’}(S_{t+1} |S_t=a,A_t=a)\right] \tag{9}\\
& = max_{a} \sum_{s’,r}p(s’,r|s,a)\left[r+v_{\pi’}(s’) \right]
\end{align*}
这和贝尔曼最优等式是一样的???殊途同归!!!
但是,需要说的一点是,目前我们假设的$\pi$和$\pi’$是deterministic,当$\pi$是stochastic情况的时候,其实也是一样的。只不过,原来我们每次选择的是使得$v_{\pi}$最大的action。对于stochastic的情况来说,输出的是每个动作的概率,可能有几个动作都能使得value function最大,那就让这几个动作的概率一样大,比如是$n$个动作,都是$\frac{1}{n}$。
Policy Iteration
我们已经讲了Policy Evaluation和Policy Improvement,Evalution会计算出一个固定$\pi$的value function,Improvment会根据value function改进这个policy,然后计算出一个新的policy $\pi’$,对于新的策略,我们可以再次进行Evaluation,然后在Improvement,就这样一直迭代,对于有限的MDP,我们可以求解出最优的value function和policy。这就是Policy Iteration算法。
Policy Iteration算法
1.初始化
$V(s)\in R,\pi(s) in A(s)$
$\qquad$
2.Policy Evaluation
Loop
$\qquad\Delta\leftarrow 0 $
$\qquad$ For each $s\in S$
$\qquad\qquad v\leftarrow V(s)$
$\qquad\qquad V(s)\leftarrow \sum_{s’,r}p(s’,r|s,a)\left[r+\gamma V(s’)\right]$
$\qquad\qquad \Delta \leftarrow max(\Delta, |v-V(s)|) $
until $\Delta \lt \theta$
3.Policy Improvement
$policy-stable\leftarrow true$
For each $s \in S$
$\qquad old_action = \pi(s)$
$\qquad \pi(s) = argmax_a \sum_{s’,a’}p(s’,r|s,a)\left[r+\gamma V(s’)\right]$
$\qquad If\ old_action \neq \pi(s), policy-stable\leftarrow false$
If policy-stable,停止迭代,返回$V$和$\pi$,否则回到2.Policy Evalution继续执行。
Value Iteration
从Policy Iteration算法中我们可以看出来,整个算法分为两步,第一步是Policy Evaluation,第二步是Policy Improvement。而每一次Policy Evaluation都要等到Value function收敛到一定程度才结束,这样子就会非常慢。一个替代的策略是我们尝试每一次Policy Evaluation只进行几步的话,一种特殊情况就是每一个Policy Evaluation只进行一步,这种就叫做Value Iteration。给出如下定义:
\begin{align*}
v_{k+1}(s) &= max_a \mathbb{E}\left[R_{t+1} + \gamma v_k(S_{t+1})| S_t=s, A_t = a\right]\\
&= max_a \sum_{s’,r}p(s’,r|s,a) \left[r+\gamma v_k(s’)\right] \tag{10}
\end{align*}
它其实就是把两个步骤给合在了一起,原来分开是:
\begin{align*}
v_{\pi}(s) &= \mathbb{E}\left[R_{t+1} + \gamma v_k(S_{t+1})| S_t=s, A_t = a\right]\\
&= \sum_{s’,r}p(s’,r|s,a) \left[r+\gamma v_k(s’)\right]\\
v_{\pi’}(s) &= max_a \sum_{s’,r}p(s’,r|s,a) \left[r+\gamma v_{\pi}(s’)\right]\\
\end{align*}
另一种方式理解式$(10)$可以把它看成是使用贝尔曼最优等式进行迭代更新,Policy Evaluation用的是贝尔曼期望等式进行更新。下面给出完整的Value Iteration算法
Value Iteration 算法
初始化
阈值$\theta$,以及随机初始化的$V(s), s\in S^{+}$,$V(terminal)=0$。
Loop
$\qquad v\leftarrow V(s)$
$\qquad$Loop for each $s\in S$
$\qquad\qquad V(s) = max_a\sum_{s’,r}p(s’,r|s,a)\left[r+\gamma V(s’)\right]$
$\qquad\qquad\Delta \leftarrow max(Delta, |v-V(s)|)$
until $\Delta \lt \theta$
返回 输出一个策略$\pi\approx\pi_{*}$,这里书中说是deterministic,我觉得都可以,$\pi$也可以是stochastic的,最后得到的$\pi$满足:
$\pi(s) = argmax_a\sum_{s’,r}p(s’,r|s,a)\left[r+\gamma V(s’)\right]$
Asychronous Dynamic Programming
之前介绍的这些DP方法,在每一次操作的时候,都有对所有的状态进行处理,这就很耗费资源。所以这里就产生了异步的DP算法,这类算法在更新的时候,不会使用整个的state set,而是使用部分state进行更新,其中一些state可能被访问了很多次,而另一些state一次也没有被访问过。
其中一种异步DP算法就是在plicy evalutaion的过程中,只使用一个state。
使用DP算法并不代表一定能减少计算量,他只是减少在策略没有改进之前陷入无意义的evaluation的可能。尽量选取那些重要的state用来进行更新。
同时,异步DP方便进行实时的交互。在使用异步DP更新的时候,同时使用一个真实场景中的agent经历进行更新。智能体的experience可以被用来确定使用哪些state进行更新,DP更新后的值也可以用来指导智能体的决策。
Generalized Policy Iteration
之前介绍了三类方法,Policy Iteration,Value iteration以及Asychronous DP算法,它们都有两个过程在不断的迭代进行。一个是evaluation,一个是improvement,这类算法统一的被称为Generalized Policy Iteration(GPI),可以根据不同的粒度进行细分。基本上所有的算法都是GPI,policy使用value function进行改进,value function朝着policy的真实值函数改进,如果value function和policy都稳定之后,那么说他们都是最优的了。
GPI中evalution和improvemetnt可以看成既有竞争又有合作。竞争是因为evaluation和improment的方向通常是相对的,policy改进意味着value function不适用于当前的policy,value function更新意味着policy不是greedy的。然后长期来说,他们共同作用,想要找到最优的值函数和policy。
GPI可以看成两个目标的交互过程,这两个目标不是正交的,改进一个目标也会使用另一个目标有所改进,直到最后,这两个交互过程使得总的目标变成最优的。
Efficiency of Dynamic Programming
用$n$和$k$表示MDP的状态数和动作数,DP算法保证在多项式时间内找到最优解,即使策略的总数是$k^n$个。
DP比任何在policy space内搜索的算法要快上指数倍,因为policy space搜索需要检查每一个算法。Linear Programming算法也可以用来解MDP问题,在某些情况下最坏的情况还要比DP算法快,但是LP要比只适合解决state数量小的问题。而DP也能处理states很大的情况。
Summary
- 使用贝尔曼公式更新值函数,可以使用backup diagram看他们的直观表示。
- 基本上所有的强化学习算法都可以看成GPI(generalized policy iteraion),先评估某个策略,然后改进这个策略,评估新的策略…这样子循环下去,直到收敛,找到一个不在变化的最优值函数和策略。
GPI不一定是收敛的,本章介绍的这些大多都是收敛的,但是还有一些没有被证明收敛。 - 可以使用异步的DP算法。
- 所有的DP算法都有一个属性叫做bootstrapping,即基于其他states的估计更新每一个state的值。因为每一个state value的更新都需要用到他们的successor state的估计。
They update estimates onthe basis of other estimates。