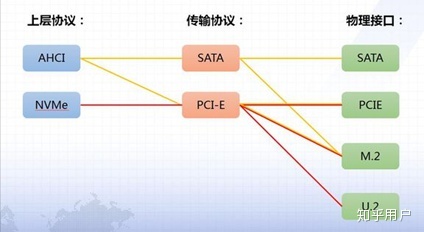
常见的日志文件
/var/log/cron.log crontab调度有没有执行,有没有错误以及/etc/crontab是否正确编写
/var/log/lastlog 所有账号最后一次的登录信息,非ASCII文件
/var/log/mail.log 所有邮件的往来信息
/var/log/messages 各种错误信息
/var/log/secure
/var/log/wtmp 登录成功与识别的账号信息
/var/log/apport.log 应用程序崩溃记录
/var/log/apt/* apt-get 安装卸载软件的日志
/var/log/auth.log 登录认证log(与/etc/var/secure挺像)
/var/log/boot.log 系统启动的日志
/var/log/btmp 记录所有失败者的信息
/var/log/cups/*
/var/log/dist-upgrade dist-upgrade这种更新方式的日志
/var/log/dmesg 内核缓冲信息
/var/log/dpkg.log 安装或dpkg命令清除软件包的日志
/var/log/faillog 用户登录失败信息,错误登录命令也会显示
/var/log/fontconfig.log 字体设置有关的日志
/var/log/fsck 文件系统日志
/var/log/hp
/var/log/install
/var/log/kern.log 内核产生的日志
/var/log/samba samba存储的信息
/var/log/syslog 系统登录信息
/var/log/upstart
/var/log/wtmp 包含登录信息,找出谁正在登录进入系统以及谁用命令显示这个文件或者信息等
/var/log/xorg.*.log 来自X的日志信息