文件和文件夹查看
- 查看文件和文件夹
dir - 只查看文件夹
dir /ad
dir /a:d - 只查看文件
文件和文件夹删除
- 删除文件
del file_name - 删除目录
rd dir_name
在数学上有专门的翻译,非平凡的。
trivial是无足轻重的,不重要的,所以non-trivial是有一定规模的,复杂的。
图片变化,指的是将输入经过线性变换成均值为0和单位方差的数据。。我是在batch_normalization论文中遇到的。
出现在ReLU论文中,用来形容激活函数,saturating指的是输出挤压在一个区间内。
这里会介绍下面三种init系统
Linux的启动从BIOS开始,bootloader载入内核,进行内核初始化。内核初始化的最后一步是启动pid为$1$的init进程。这个进程是系统的第一个进程,它负责产生其他所有用户进程。
Init系统能够定义、管理和控制init进程的行为。它负责组织和运行许多独立的或相关的始化job(因此被称为init系统),从而让计算机系统进入某种用户规定的run level。
大多数Linux发行版的init 系统是和 System V 相兼容的,称为 SysVInit。Ubuntu和RHEL采用upstart替代了SysVInit。而 Fedora 从版本15开始使用SystemD的新init系统。ubuntu-16.10之后开始不再使用SysVInt管理系统,改用SystemD。
SysVInit的最大缺点是主要依赖于 Shell 脚本,启动太慢。
SysVInit检查/etc/inittab文件中是否含有’initdefault’ 项,然后进入默认run level。如果没有默认的run level,用户手动决定进入哪个run level。SysVInit通常会有8种run-level,0到6和S或者s。但 0,1,6 run level的操作是公认的: 0代表关机, 1代表单用户模式, 6代表重启,其他run level跟发行版有关。/etc/inittab 文件中还定义了各种run level需要执行的初始化工作。
SysVInit用脚本,文件命名规则和软链接来实现不同的runlevel。首先,SysVInit 需要读取/etc/inittab 文件,获得以下配置信息:
得到配置信息后,SysVInit 顺序地执行以下初始化步骤将系统初始化为相应的runlevel X。
首先运行rc.sysinit完成以下任务。
接下来运行/etc/rc.d/rc脚本。根据不同的runlevel,rc脚本打开对应该runlevel的rcX.d目录,以S开头的脚本是启动时运行的脚本,S后面的数字定义了这些脚本的执行顺序。
rc.local是自定义脚本存放目录。
关闭顺序的控制也是依靠/etc/rc.d/rcX.d/目录下所有脚本的命名规则来控制的,所有以K开头的脚本都将在关闭系统时调用,K后的数字规定了执行顺序。这些脚本负责安全地停止service或者其他的关闭job。
SysVInit包含了一系列启动,运行和关闭所有其他程序的工具和命令。
Ubuntu使用upstart init系统,没有/etc/inittab文件。Upstart解决了热插拔以及网络共享盘的挂载问题。在/etc/fstab 中,可以指定系统自动挂载一个网络盘,比如 NFS等,SysVInit 分析/etc/fstab 挂载文件系统这个步骤是在网络启动之前。可是如果网络没有启动,NFS或者iSCSI服务都不可访问,当然也无法进行挂载操作。SysVInit采用netdev的方式来解决这个问题,即/etc/fstab发现netdev属性挂载点的时候,不尝试挂载它,在网络初始化之后,有专门的netfs service来挂载所有这些网络盘。
UpStart 解决了之前提到的 SysVInit 的缺点。采用event驱动模型,UpStart 可以:
Job是一个job unit,用来完成一件工作,比如启动一个后台service,或者运行一个配置命令。每个 Job 都等待一个或多个event,一旦event发生,upstart 就触发该job完成相应的工作。
Job是一个job的unit,一个task或者一个service。可以理解为SysVInit中的一个service脚本。有三种类型的job:
还可以根据Upstart初始化的范围对job进行分类。系统的初始化任务叫做system job,比如挂载文件系统的任务就是一个system job;用户会话的初始化service就叫做 session job。
Upstart为每个job都维护一个生命周期。一般来说,job有开始,运行和结束。以及其他更精细的状态,比如开始有开始之前(pre-start),即将开始(starting)和已经开始了(started)几种不同的状态,这样可以更加精确地描述job的当前状态。详细的状态如下表所示:
| 状态名 | 含义 |
|---|---|
| Waiting | 初始状态 |
| Starting | Job 即将开始 |
| pre-start | 执行 pre-start 段,即任务开始前应该完成的job |
| Spawned | 准备执行 script 或者 exec 段 |
| post-start | 执行 post-start 动作 |
| Running | interim state set after post-start section processed denoting job is running (But it may have no associated PID!) |
| pre-stop | 执行 pre-stop 段 |
| Stopping | interim state set after pre-stop section processed |
| Killed | 任务即将被停止 |
| post-stop | 执行 post-stop 段 |
当job的状态即将发生变化的时候,init 进程会发出相应的event(event),如下图是job的状态机。其中只有四个状态Starting,Started,Stopping,Stopped会引起init进程发送相应的event,而其它的状态变化不会发出event。
Event在upstart中以通知消息的形式具体存在。一旦某个event发生了,Upstart 就向整个系统发送一个消息。Event 可以分为三类: signal,methods 或者 hooks。
不同的 Linux 发行版对 upstart 有不同的定制和实现,实现和支持的event也有所不同,可以用man 7 upstart-events来查看event列表。
Upstart是由event触发job运行的一个系统,每一个程序的运行都由其依赖的event发生而触发的。系统初始化时,init进程开始运行,init进程自身会发出不同的event,这些event会触发一些job运行。每个job运行过程中会释放不同的event,这些event又将触发新的job运行。如此反复,直到整个系统正常运行起来。
每一个Job都是由一个job配置文件(Job Configuration File)定义的。job配置文件存放在/etc/init下面,是以.conf 作为文件后缀的文件。
~$:cat /etc/init/anacron.conf
1 | # anacron - anac(h)ronistic cron |
“expect” Stanza
为了启动,停止,重启和查询某个系统service。Upstart 需要跟踪该service所对应的进程。部分service为了将自己变成daemon,会采用fork调用, UpStart必须采用fork出来的进程号作为service的 PID。但是,UpStart 本身无法判断service进程是否fork了,所以需要指定expect告诉 UpStart 进程是否fork了。"expect fork"表示进程只会 fork 一次;"expect daemonize"表示进程会 fork 两次。
“exec” Stanza 和"script" Stanza
"exec"关键字配置job需要运行的命令,"script"关键字定义需要运行的脚本。
1 | # mountall.conf |
该job在系统启动时运行,负责挂载所有的文件系统。该job需要执行复杂的脚本,由"script"关键字定义;在脚本中,使用了 exec 来执行 mountall 命令。
“start on” Stanza 和"stop on" Stanza
"start on"定义了触发job的所有event。"start on"的语法很简单,如下所示:
start on EVENT [[KEY=]VALUE]… [and|or…]
EVENT 表示event的名字,可以在 start on 中指定多个event,表示该job的开始需要依赖多个event发生。多个event之间可以用 and 或者 or 组合,"表示全部都必须发生"或者"其中之一发生即可"等不同的依赖条件。除了event发生之外,job的启动还可以依赖特定的条件,因此在 start on 的 EVENT 之后,可以用 KEY=VALUE 来表示额外的条件,一般是某个环境变量(KEY)和特定值(VALUE)进行比较。如果只有一个变量,或者变量的顺序已知,则 KEY 可以省略。
"stop on"定义job在什么情况下需要停止。
1 | #dbus.conf |
D-Bus 是一个系统消息service,上面的配置文件表明当系统发出 local-filesystems event时启动 D-Bus;当系统发出 deconfiguring-networking event时,停止 D-Bus service。
Session 就是一个用户会话,即用户从远程或者本地登入系统开始job,直到用户退出,整个过程构成一个会话。用户往往会为自己的会话做一个定制,如添加特定的命令别名等等。这些job都属于对特定会话的初始化操作,被称为 Session Init。在字符模式下,会话初始化相对简单。用户登录后只能启动一个 Shell,通过 shell 命令使用系统。各种 shell 程序都支持一个自动运行的启动脚本,比如~/.bashrc。用户在这些脚本中加入需要运行的定制化命令。在图形界面下,用户登录后看到的并不是一个 shell 提示符,而是一个桌面。一个完整的桌面环境包括 window manager,panel以及其它一些定义在/usr/share/gnome-session/sessions/下面的基本组件,此外还有一些辅助的应用程序,,比如 system monitors,panel applets,NetworkManager,Bluetooth,printers 等。当用户登录之后,这些组件都需要被初始化。目前启动各种图形组件和应用的job由 gnome-session 完成。过程如下:
以 Ubuntu 为例,当用户登录 Ubuntu 图形界面后,显示管理器(Display Manager)lightDM 启动 Xsession。Xsession 接着启动 gnome-session,gnome-session 负责其它的初始化job,然后就开始了一个 desktop session。如下所示,是传统的desktop session 启动过程:
1 | init |
但是事实上一些应用和组件并不需要在会话初始化过程中启动,而是需要在需要它们的时候才启动。比如 Network Manager,一天之内用户很少切换网络设备,所以大部分时间 Network Manager service仅仅是在浪费系统资源。UpStart的基于event的按需启动的模式就可以很好地解决这些问题。下面给出了采用UpStart之后的会话初始化过程:
1 | init |
Upstart 的运作完全是基于job和event的。Job的状态变化和运行会引起event,进而触发其它job和event。而SysVInit是基于运行级别的,因为历史的原因,Linux 上的多数软件还是采用传统的 SysVInit 脚本启动方式,所以UpStart还是必须模拟老的SysVInit的run level,以便和多数现有软件兼容。
下图描述了 UpStart 的启动过程。

系统上电后运行GRUB载入内核。内核执行硬件初始化和内核自身初始化。在内核初始化的最后,内核将启动pid为1的Upstart init 进程。Upstart 进程执行一些自身的初始化job后,立即发出"startup" event。上图中用红色方框加红色箭头表示event,可以在左上方看到"startup"event。
所有依赖于"startup"event的job被触发,其中最重要的是mountall。mountall jog负责挂载系统中需要使用的文件系统,完成相应job后,mountall任务会发出以下event:local-filesystem,virtual-filesystem,all-swaps,
其中 virtual-filesystem event触发 udev 任务开始job。任务 udev 触发 upstart-udev-bridge 的job。Upstart-udev-bridge 会发出 net-device-up IFACE=lo event,表示本地回环 IP 网络已经准备就绪。同时,任务 mountall 继续执行,最终会发出 filesystem event。此时,任务 rc-sysinit 会被触发,因为 rc-sysinit 的 start on条件如下:
1 | start on filesystem and net-device-up IFACE=lo |
任务rc-sysinit调用telinit。Telinit任务会发出 runlevel event,触发执行/etc/init/rc.conf。rc.conf 执行/etc/rc$.d/目录下的所有脚本,和 SysVInit 非常类似。
1 | alsa-mixer-save stop/waiting |
第一列是job名,比如 rsyslog。第二列是job的目标;第三列是job的状态。
UpStart 还提供了一些快捷命令来简化 initctl。比如 reload,restart,start,stop 等等。启动一个service可以简单地调用
~$:start job
这和执行 initctl start job是一样的效果。
一些命令是为了兼容其它系统(主要是 SysVInit),比如显示 runlevel 用/sbin/runlevel 命令:
~$:runlevel
> N 2
在 Upstart 系统中,需要修改/etc/init/rc-sysinti.conf 中的 DEFAULT_RUNLEVEL 这个参数,以便修改默认启动运行级别。这一点和 SysVInit 的习惯有所不同,大家需要格外留意。
SystemD和SysVInit 和 LSB init scripts 兼容,以及更快的启动速度,SystemD 提供了比 UpStart 更激进的并行启动能力。
为了减少系统启动时间,SystemD 的目标是尽可能启动更少的进程和尽可能将更多进程并行启动,同样地,UpStart 也试图实现这两个目标。UpStart 采用event驱动机制,当service需要的时候才通过event触发启动;不相干的service可以并行启动。下面的图形演示了 UpStart 相对于 SysVInit 在并发启动这个方面的改进:

假设有 7 个不同的启动项目, 比如 JobA、Job B 等等。在 SysVInit 中,每一个启动项目都由一个独立的脚本负责,它们由 SysVInit 顺序地,串行地调用。因此总的启动时间为 T1+T2+T3+T4+T5+T6+T7。其中一些任务有依赖关系,比如 A,B,C,D。而Job E和F却和A,B,C,D无关。这种情况下,UpStart 能够并发地运行任务{E,F,(A,B,C,D)},使得总的启动时间减少为 T1+T2+T3。但是在 UpStart 中,有依赖关系的service还是必须先后启动。
让我们例举一些例子, Avahi service需要 D-Bus 提供的功能,因此 Avahi 的启动依赖于 D-Bus,UpStart 中,Avahi 必须等到 D-Bus 启动就绪之后才开始启动。类似的,livirtd 和 X11 都需要 HAL service先启动,而所有这些service都需要 syslog service记录日志,因此它们都必须等待 syslog service先启动起来。然而 httpd 和他们都没有关系,因此 httpd 可以和 Avahi 等service并发启动。
SystemD 能够更进一步提高并发性,即便对于那些 UpStart 认为存在相互依赖而必须串行的service,比如 Avahi 和 D-Bus 也可以并发启动。从而实现如下图所示的并发启动过程:

所有的任务都同时并发执行,总的启动时间被进一步降低为 T1。

如果 UpStart 找错了,将 p1作为service进程的 Pid,那么停止service的时候,UpStart 会试图杀死 p1进程,而真正的 p1进程则继续执行。换句话说该service就失去控制了。还有更加特殊的情况。比如,一个 CGI 程序会fork两次,从而脱离了和 Apache 的父子关系。当 Apache 进程被停止后,该 CGI 程序还在继续运行。而我们希望service停止后,所有由它所启动的相关进程也被停止。为了处理这类问题,UpStart 通过 strace 来跟踪 fork、exit 等系统调用,但是这种方法很笨拙,且缺乏可扩展性。SystemD 则利用了 Linux 内核的特性即 CGroup 来完成跟踪的任务。当停止service时,通过查询 CGroup,SystemD 可以确保找到所有的相关进程,从而干净地停止service。CGroup 已经出现了很久,它主要用来实现系统资源配额管理。CGroup 提供了类似文件系统的接口,使用方便。当进程创建子进程时,子进程会继承父进程的 CGroup。因此无论service如何启动新的子进程,所有的这些相关进程都会属于同一个 CGroup,SystemD 只需要简单地遍历指定的 CGroup 即可正确地找到所有的相关进程,将它们一一停止即可。
一个service可以认为是一个unit;一个挂载点是一个unit;一个交换分区的配置是一个unit;等等,总共有12种unit
虽然 SystemD 将大量的启动job解除了依赖,使得它们可以并发启动。但还是存在有些任务,它们之间存在天生的依赖,不能用"套接字激活"(socket activation)、D-Bus activation 和 autofs 三大方法来解除依赖(三大方法详情见后续描述)。比如:挂载必须等待挂载点在文件系统中被创建;挂载也必须等待相应的物理设备就绪。为了解决这类依赖问题,SystemD 的配置单元之间可以彼此定义依赖关系。
SystemD 用配置单元定义文件中的关键字来描述配置单元之间的依赖关系。比如:unit A 依赖 unit B,可以在 unit B 的定义中用"require A"来表示。这样 SystemD 就会保证先启动 A 再启动 B。
SystemD 能保证事务完整性。SystemD 的事务概念和数据库中的有所不同,主要是为了保证多个依赖的配置单元之间没有环形引用。比如 unit A、B、C,假如它们的依赖关系为:

存在循环依赖,那么 SystemD 将无法启动任意一个service。此时 SystemD 将会尝试解决这个问题,因为配置单元之间的依赖关系有两种:required 是强依赖;want 则是弱依赖,SystemD 将去掉 wants 关键字指定的依赖看看是否能打破循环。如果无法修复,SystemD 会报错。
SystemD 能够自动检测和修复这类配置错误,极大地减轻了管理员的排错负担。
SystemD 用目标(target)替代了运行级别的概念,提供了更大的灵活性,如您可以继承一个已有的目标,并添加其它service,来创建自己的目标。下表列举了 SystemD 下的目标和常见 runlevel 的对应关系:
SysVInit 运行级别|SystemD 目标|备注
0|runlevel0.target, poweroff.target|关闭系统。
1, s, single|runlevel1.target, rescue.target|单用户模式。
2, 4|runlevel2.target, runlevel4.target, multi-user.target|用户定义/域特定运行级别。默认等同于 3。
3|runlevel3.target, multi-user.target|多用户,非图形化。用户可以通过多个控制台或网络登录。
5|runlevel5.target, graphical.target|多用户,图形化。通常为所有运行级别 3 的service外加图形化登录。
6|runlevel6.target, reboot.target|重启
emergency|emergency.target|紧急Shell
并发启动原理之一:解决 socket 依赖
并发启动原理之二:解决 D-Bus 依赖
并发启动原理之三:解决文件系统依赖
~$:systemctl list-units # 列出正在运行的 Unit
~$:systemctl list-units --all # 列出所有Unit,包括没有找到配置文件的或者启动失败的
~$:systemctl list-units --all --state=inactive # 列出所有没有运行的 Unit
~$:systemctl list-units --failed # 列出所有加载失败的 Unit
~$:systemctl list-units --type=service # 列出所有正在运行的、类型为 service 的 Unit
~$:systemctl list-unit-files # 列出所有配置文件
~$:systemctl list-unit-files --type=service # 列出指定类型的配置文件
~$:systemctl start foo.service # 用来启动一个service (并不会重启现有的)
~$:systemctl stop foo.service # 用来停止一个service (并不会重启现有的)。
~$:systemctl restart foo.service # 用来停止并启动一个service。
~$:systemctl reload foo.service # 当支持时,重新装载配置文件而不中断等待操作。
~$:systemctl condrestart foo.service # 如果service正在运行那么重启它。
~$:systemctl status foo.service # 汇报service是否正在运行。
~$:systemctl list-unit-files --type=service # 用来列出可以启动或停止的service列表。
~$:systemctl enable foo.service # 在下次启动时或满足其他触发条件时设置service为启用
~$:systemctl disable foo.service # 在下次启动时或满足其他触发条件时设置service为禁用
~$:systemctl is-enabled foo.service # 用来检查一个service在当前环境下被配置为启用还是禁用。
~$:systemctl list-unit-files --type=service # 输出在各个运行级别下service的启用和禁用情况
~$:systemctl daemon-reload # 创建新service文件或者变更设置时使用。
~$:systemctl isolate multi-user.target (OR systemctl isolate runlevel3.target OR telinit 3) # 改变至多用户运行级别
~$:ls /etc/SystemD/system/*.wants/foo.service # 用来列出该service在哪些运行级别下启用和禁用。
~$:systemctl reboot # 重启机器
~$:systemctl poweroff # 关机
~$:systemctl suspend # 待机
~$:systemctl hibernate # 休眠
~$:systemctl hybrid-sleep # 混合休眠模式(同时休眠到硬盘并待机)
一般只有管理员才可以关机。正常情况下系统不应该允许 SSH 远程登录的用户执行关机命令。否则其他用户正在job,一个用户把系统关了就不好了。使用logind解决这个问题。logind 不是 pid-1 的 init 进程。它的作用和 UpStart 的 session init 类似,但功能要丰富很多,它能够管理几乎所有用户会话(session)相关的事情。logind 不仅是 ConsoleKit 的替代,它可以:
SysVInit比较简单。Service开发人员只需要编写启动和停止脚本,将 service 添加/删除到某个 runlevel 时,只需要执行一些创建/删除软连接文件的基本操作。
其次,SysVInit 的另一个优点是确定的执行顺序:脚本严格按照启动数字的大小顺序执行,一个执行完毕再执行下一个,这非常有益于错误排查。UpStart 和 SystemD 支持并发启动,导致没有人可以确定地了解具体的启动顺序,排错不易。但是串行地执行脚本导致 SysVInit 运行效率较慢。
可以看到,UpStart 的设计比 SysVInit 更加先进。
SystemD 的最大特点有两个:并发启动能力强,极大地提高了系统启动速度;用 CGroup 统计跟踪子进程,干净可靠。
此外,和其前任不同的地方在于,SystemD 已经不仅仅是一个初始化系统了。SystemD 出色地替代了 SysVInit 的所有功能,但它并未就此自满。因为 init 进程是系统所有进程的父进程这样的特殊性,SystemD 非常适合提供曾经由其他service提供的功能,比如定时任务 (以前由 crond 完成);会话管理 (以前由 ConsoleKit/PolKit 等管理) 。
1.https://www.ibm.com/developerworks/cn/linux/1407_liuming_init1/index.html
2.https://www.ibm.com/developerworks/cn/linux/1407_liuming_init2/index.html?ca=drs-
3.https://www.ibm.com/developerworks/cn/linux/1407_liuming_init3/index.html?ca=drs-
4.http://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-commands.html
想要找到初始化指定长度list最快的方法。
方法一:
1 | length = 10 |
方法二
1 | length = 10 |
事实上,只有第二种方法是对的。第一种方法中,arrary中的10个[]都指向了同一个对象。。
1 | length = 10 |
管道命令仅会处理stdout并不会处理stderrout,管道命令必须要能接受前一个命令传回来的数据成为stdinput
1 | cut -d '分隔字符' -f (fields)fields为数字 |
1 | cut -d ':' -f 2,3 |
1 | grep [-aincv] [--color=auto] '关键字' filename |
1 | grep '^the' file |
dmesg 查看内核信息
dmesg | grep -n A3 B2 ‘eth’
A --after B --before
last | grep ‘mxx’ | cut -d ‘’ -f 1
1 | sort 排序 |
1 | sort -t ':' -k 3 -n /etc/passwd |
uniq 去重
[-il] [file]
-i 不区分大小写
-c 进行计数
last | cut -d ' ' -f 1 | sort | uniq
首先需要排序 才能去重
last | cut -d ’ ’ -f 1 | sort | uniq -c
tee双重重定向将一份数据可以同时传到文件内以及屏幕中
last | tee last.list | sort
tr 删除一段文字或者对文字内容进行替换(如删除dos中的换行符^M)
[-ds]
-d 删除信息中的某个字串
-s 替换重复字符
last | tr '[a-z]' '[A-Z]'
echo $PATH -d ':/'
cat /root/passwd | tr -d '\r' > passwd.linux
col 简单处理
[-xb]
-x 将tab键换成空格键
cat manpath.config | col -x | cat -A | more
join 将两个文件中具有相同数据的一行相加
join [-ti12] file1 file2
-i 大小写忽视
join -t ‘:’ passwd shadow
join -t ‘:’ -1 4 passwd -2 3 group
paste直接将两行粘在一起,默认并以tab键分开
-d后面可以加分隔字符默认以tab分隔
-表示来自standard input的数据的意思
paste shadow passwd
cat shadow | paste passwd - | head -n 3
expand将tab键换成空格默认是8个空格
-t 参数可以自行设定空格数
nl file | expand -t 6 - | cat -A
split [-bl] file PREFIX
-b后面加文件欲切割成的文件大小
-l以行数来切割
split -b 1M /etc/termcap termcap
ls -l termcap*
cat termcap* >> termcapback
ls -l / | spilt -l 10 -lsroot
wc -l lsroot
xargs产生某个命令的参数
[-pne0]
-p 执行每个命令询问用户
-e 是EOF的意思,后面可接一个字符,当xargs遇到这个字符,便会停止 操作
-n 后面接次数,每次command命令执行时,要使用几个参数
-用来代替stdout以及stdin
tar -cvf - /home | tar xvf -
[-in]
-i 直接修改文件内容
-n 静默
-e 直接在shell下编辑
-c replace
-a append
-p print
nl file | sed '2,3d’
nl file | sed '$a add a test’
nl file | sed -n '5,7p’
nl file | sed '2,5c jkadfk
>fdasf
>asfddf '
nl file | sed ‘s/s_place/s_replace/g’
nl file | sed ‘/^$/d’
egrep -n ‘$|#’ file
egrep -n ‘go?d’ file 0个或者一个?之前的字符
egrep -n ‘go+d’ file 一个及以上+之前的字符
grep -n 'god’ file 0个或者0个以上之前的字符
printf ‘%s\t %s\t %s\t \n’ $(cat file)
printf ‘%10s %5i %5i \n’ $(cat file)
last | awk '{print $1 “\t” S3 “\t” $4 NF NR}'
cat /etc/passwd | awk ‘BEGIN {FS=":"} $3 < 10 {print $1 “\t” $3 }’
cat /etc/passwd | awk ‘NR==1{printf "%10s %10s %10s %10s “,$1,$2,$3,“tot al”}
NR>=2{total=$2+$3;
printf “%10s %10d %10d %## f”,$1,$2,$3,total”}’
rsync相对于scp有以下优点:
1.支持断点续传
2.支持ssh
3.可分块传输
~$:rsync options source destination
rsync [-zvra] source destination
-z 传输前进行压缩
-v 显示详细信息
-r 递归拷贝
-a 保留时间戳,owner,group
-e ssh 使用ssh
–partial 单个文件的断点续传
–progress 显示同步进度
-P等于–paritial和–progress一同使用
–include 只同步某些目录
–exclude 不同步某些目录
~$:rsync -avc --exclude=**pycache --exclude=**data --exclude=**tmp --exclude=**result_pictures experimental/ ~/
~$:rsync -rP source_dir target_dir
1.https://stackoverflow.com/questions/4585929/how-to-use-cp-command-to-exclude-a-specific-directory
2.https://www.cnblogs.com/bangerlee/archive/2013/04/07/3003243.html
ssh是一种安全传输协议,此外还有tunnel转发功能,可以用来内网渗透。
-L port:host:hostport,访问本机的port端口就相当于访问host的hostport端口。
将本机的某个端口转发到远端指定机器的指定端口。本机上分了一个socket监听port端口,一旦该端口有了连接,就通过一个ssh转发出去。
-R port:host:hostport,将远程主机的某个端口转发到指定的本地机器的指定端口。远程主机上分了一个socket监听port端口,一旦该端口有了连接,就通过一个ssh转发到指定的本地机器的指定端口。
-N 不指定脚本或者命令
-f 后台认证,需要和-N连用
-L和-R的区别,-L是ssh隧道,-R是ssh反向隧道。
执行以下命令的本机(localhost)通过中间服务器(45.32.22.289)访问被屏蔽的网站(google)。
~$:ssh -L 1234:google_ip:80 root@45.32.22.289
拿这个举个例子,可能不是很恰当,但是有助于理解。我自己的机器(A)是不能访问google©的,但是我有一台vps(B),地址为45.32.22.289是可以访问google的,可以通过ssh隧道将A的端口(1234)通过B映射到C的端口(80)。
~$:ssh -L 12345:10.1.114.50:6006 mxxmhh@127.0.0.1
将本机的12345端口映射到10.1.114.50的6006端口,中间服务器使用的是本机。
或者可以使用10.1.114.50作为中间服务器。
~$:ssh -L 12345:10.1.114.50:6006 liuchi@10.1.114.50
或者可以使用如下方法:
~$:ssh -L 12345:127.0.0.1:6006 liuchi@10.1.114.50
从这个方法中,可以看出127.0.0.1这个ip是中间服务器可以访问的ip。
以上三种方法中,-L后的端口号12345可以随意设置,只要不冲突即可。
然后在服务端运行以下命令:
~$:tensorboard --logdir logdir -port 6006
这个端口号也是可以任意设置的,不冲突即可。
然后在本机访问
https://127.0.0.1:12345即可。
外网A(123.123.123.123)访问处于内网B的(127.0.0.1)的机器。
~$:ssh -N -f -R 2222:127.0.0.1:22 root@123.123.123.123
可以在外网机器A(123.123.123.123)上通过如下命令访问(-R)指定的内网机器B:
~$:ssh -p 2222 userB@localhost
Host key verification failed
直接把/home/username/.ssh/known_hosts中相应的给删了。
A是家里的内网(无公网IP)上机器(196.),B是VPS(有公网IP)(45.32.),C是公司内网(无公网IP)机器(10.)。
要在家里的内网访问公司的内网,即A访问C。在C上建立ssh反向隧道:
~$:ssh -N -f -R 2222:127.0.0.1:22 userB@B.ip
在A上访问:
~$:ssh -p 2222 userC@B.ip
1.https://blog.trackets.com/2014/05/17/ssh-tunnel-local-and-remote-port-forwarding-explained-with-examples.html
2.https://blog.creke.net/722.html
3.http://arondight.me/2016/02/17/使用SSH反向隧道进行内网穿透/
这里我选择在D盘,创建目录D://Ftp作为我的ftp文件存放目录
其实这里的ftp用户就是windows 操作系统的用户,为了安全起见,我们不选我们工作时登录的用户,选择重新创建一个新的用户。这里添加了新用户ftpuser作为ftp登录用户。
打开控制面板下的程序,选择启用或关闭Windows功能,选中Internet Information Services中的FTP服务器和Web管理工具(如下图)。等待其加载完所有组件
执行完第3步以后,打开计算机管理,在服务和应用程序下我们就可以看到Internet Infromation Service,点击它,右击网站选择新建一个ftp站点,配置见下图,完成以后启动该ftp。
打开 控制面板>系统和安全>Windows防火墙>允许的应用
点击允许其他应用,这时添加windows服务主进程的路径"C:\Windows\System32\svchost.exe",这时候防火墙就允许ftp访问通过了。
在资源管理器中输入ftp://ip地址,输入账号密码后即可成功访问ftp服务器。
1 | import numpy as np |

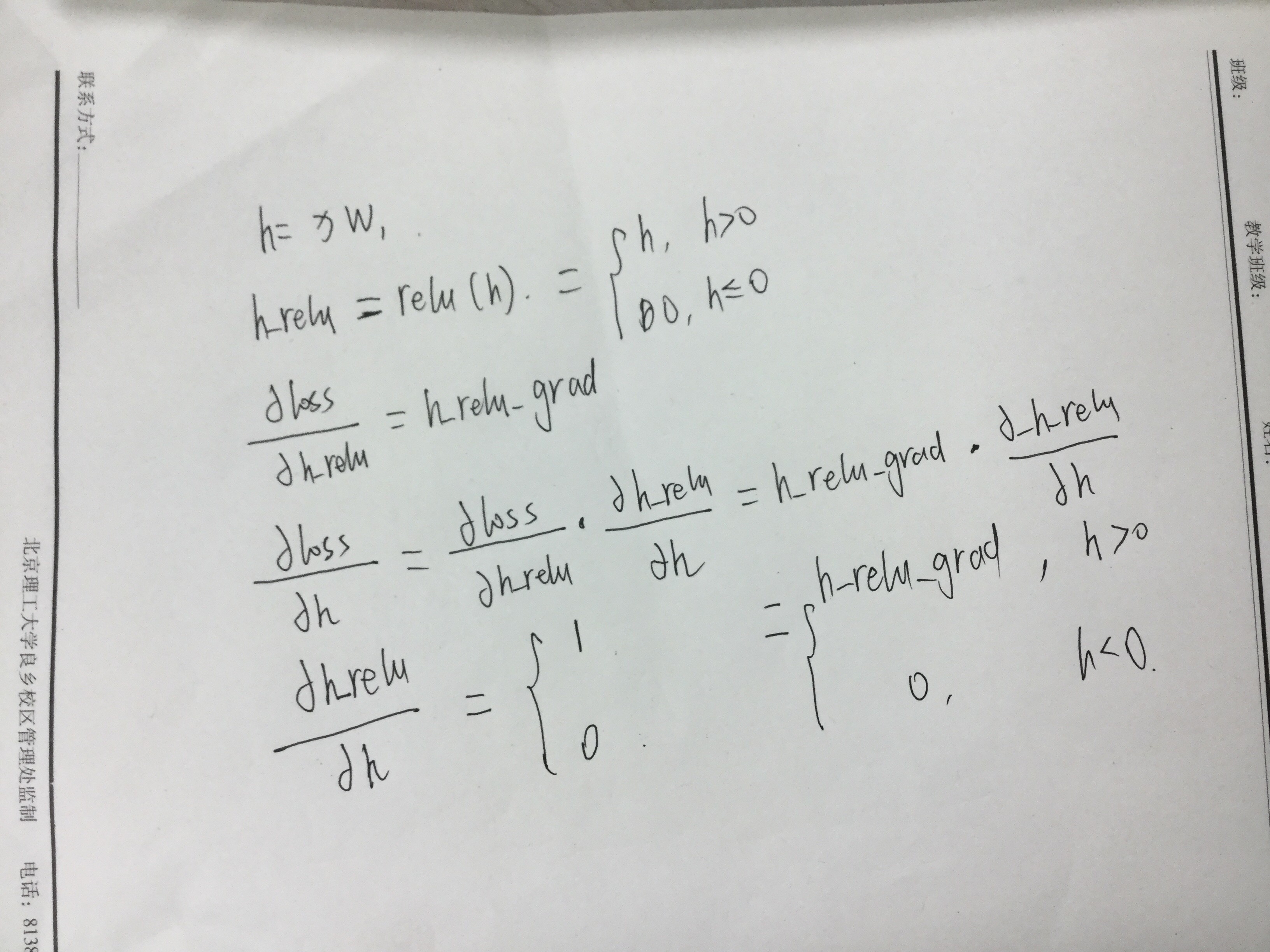
1.http://pytorch.org/tutorials/beginner/pytorch_with_examples.html
2.https://datascience.stackexchange.com/questions/27506/back-propagation-in-cnn
3.https://medium.com/@14prakash/back-propagation-is-very-simple-who-made-it-complicated-97b794c97e5c
4.https://medium.com/@pavisj/convolutions-and-backpropagations-46026a8f5d2c
5.https://becominghuman.ai/back-propagation-in-convolutional-neural-networks-intuition-and-code-714ef1c38199
6.http://www.robots.ox.ac.uk/~vgg/practicals/cnn/
7.https://www.researchgate.net/post/How_backpropagation_works_for_learning_filters_in_CNN
8.https://github.com/ivallesp/awesome-optimizers
1.https://www.zhihu.com/question/66782101/answer/579393790
2.https://www.zhihu.com/question/66782101/answer/246460048