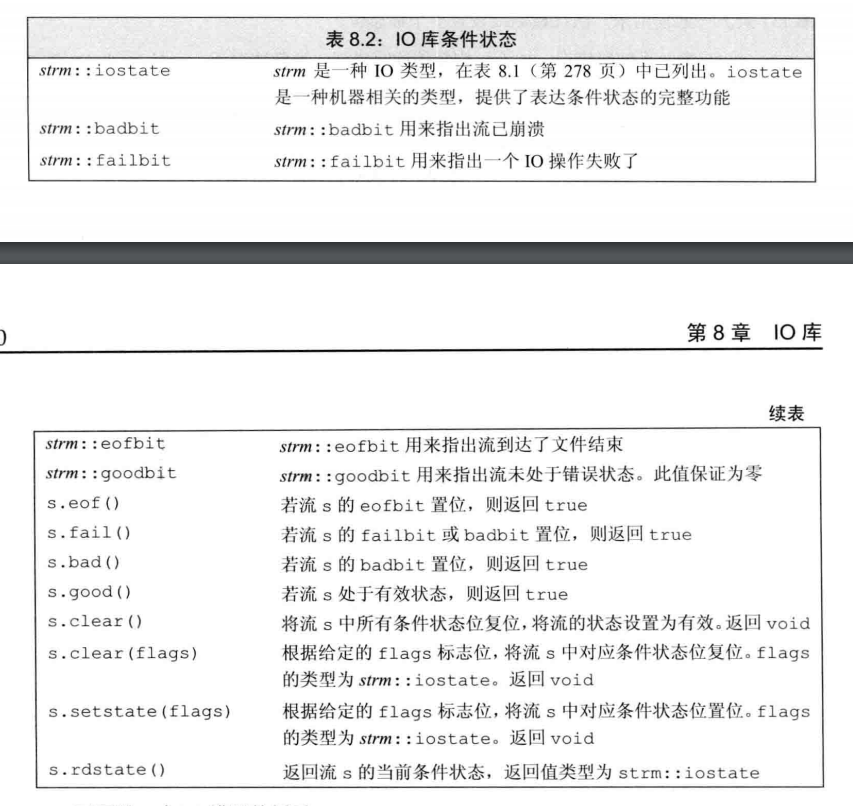
默认初始化
默认初始化,变量没有指定初值,被赋予默认值,默认值由变量类型和变量位置决定。变量类型分为内置类型和类,变量位置有函数内部和任何函数之外。
内置类型
对于内置类型的变量,如果没有显式初始化,它的位置由定义的位置决定。函数内部的内置类型不会被初始化,定义于任何函数外部的内置类型被初始化为$0$。未初始化的变量的值是未定义的。
类
对于自定义的类型来说,每个类决定初始化对象的方式,而且是否允许不经过初始化就定义对象也由自己决定。如果类允许这种行为,由类决定对象的初始值是什么;如果类要求每个对象显示初始化,在创建类对象没有进行明确的初始化操作时,会引发错误。
列表初始化
- 用花括号初始化变量。
- 无论是初始化对象或者为对象赋值,都可以使用花括号括起来的值。
- 对于内置类型来说,如果使用列表初始化,并且初始值存在丢失的风险的时候,编译器会报错。
- 可以用多个初值初始化
vector
拷贝初始化和直接初始化
使用等号进行初始化的过程叫做拷贝初始化,否则是直接初始化。
拷贝初始化和直接初始化的区别在在于:
拷贝初始化使用的拷贝构造函数,拷贝一个对象到一个新创建的对象。拷贝初始化只能提供一个初始值,因为拷贝构造函数的参数就只有一个参数。。。
直接初始化使用的是函数匹配,选择最合适的构造函数,创建一个对象。
值初始化
- 只提供给vector对象容纳的元素数量而不用略去初始值。会创建一个值初始化的元素初值,并把它赋给容器中所有元素,这个初始值由
vector对象中元素类型决定。 - 如果
vector对象中元素类型是内置类型,如int,初始值自动设置为0。 - 如果是某种类类型,比如
string,由类默认初始化。 - 有些类要求必须显式的给出初始值。如果
vector中对象不支持默认初始化,必须提供初始值。 - 如果值提供了元素的数量而没有设定初值,只能使用直接初始化。
- 初始化的真实含义依赖于传递初始值时用的是花括号还是圆括号。花括号进行列表初始化,圆括号提供的信息构造
vecotr对象。如果使用花括号中的形式,但是提供的值不能用来列表初始化,考虑使用值构造vector对象。但是如果使用圆括号提供不能构造vector对象的值,不能用来进行列表初始化。也就是说花括号可以用来列表初始化,也可以用来构建vector对象,但是圆括号只能用来构建vector对象。
特例
- 使用拷贝初始化时(使用=),只能提供一个初始值。
- 如果提供的是一个类内初始值,只能使用拷贝初始化或者花括号的形式初始化。
- 如果提供的是初始值元素的列表,只能把初始值都放在花括号里,而不能使用圆括号。
40页2.2.1节
默认初始化
内置类型由变量的类型和位置决定
类类型各自决定器初始化对象的方式
76页3.2.1节
直接初始化和拷贝初始化
88页3.3.1节
vector的列表初始化
值初始化:
内置类型,元素自动设置为0
类类型,元素由类默认初始化
300页9.2.4节
容器的列表初始化
441页13.1.1节,拷贝初始化
参考文献
1.《C++ Primer第五版》
默认初始化:
C++ Primer第五版第40页
列表初始化:
C++ Primer第五版第39页
拷贝初始化:
C++ Primer第五版第76页
值初始化:
C++ Primer第五版第91页
2.https://stackoverflow.com/questions/13461027/why-does-the-standard-differentiate-between-direct-list-initialization-and-copy
3.https://stackoverflow.com/questions/18222926/why-is-list-initialization-using-curly-braces-better-than-the-alternatives
4.https://en.cppreference.com/w/cpp/language/list_initialization
5.https://en.cppreference.com/w/cpp/utility/initializer_list