CNN
图片的表示
图像在计算机中是一堆按顺序排列的顺子,数值为0到255。0表示最暗,255表示最亮。我们可以把这堆数字用一个长长的一维数组来表示,但是这样会失去平面结构的信息,为保留该结构信息,我们通常会选择矩阵的表示方式,用一个nn的矩阵来表示一个图像。对于黑白颜色的灰度图来说,我们只需要一个nn的矩阵表示即可。对于一个彩色图像,我们会选择RGB颜色模型来表示。
在彩色图像中,我们需要用三个矩阵去表示一张图,也可以理解为一个三维张量,每一个矩阵叫做这张图片的一个channel。这个三维张量可以表示为(width,length,depth),一张图片就可以用这样一个张量来表示。
卷积神经网络(CNN)
作用
让权重在不同位置共享
filter和stride
filter又叫做kernel或者feature detector。filter会对输入的局部区域进行处理,filter处理的局部区域的范围叫做filter size。比如说一个filter的大小为(3,3),那么这个filter会一次处理width=3,length = 3的区域。卷积神经网络会用filter对整个输入进行扫描,一次移动的多少叫做stride。filter处理一次的输出为一个feature map。
depth
对于filter来说,我们一般说它的大小为(3,3)只说了它在平面的大小,但是输入的图片一般是一个RGB的三维张量,对于deepth这一个维度,如果为1的话,那么filter是(3,3),但是如果deepth大于1的话,这个filter的deepth维度一般是和张量中的deepth维度一样的。
deepth=1时,filter=(3,3),处理输入中33 个节点的值
deepth=2时,filter=(3,3),会处理输入中332个节点的值
deepth=n时,filter=(3,3),会处理输入中$33\times n$个节点的值
zero paddings
因为经过filter处理后,输入的矩阵维度会变小,所以,如果经过很多层filter处理后,就会变得越来越少,因此,为了解决这个问题,提出了zero paddings,zero padding是在filter要处理的输入上,在输入的最外层有选择的加上一行(列)或多行(列)0,从而保持输入经过filter处理之后形状不变。
feature map
一个filter的输出就是一个feature map,该feature map的width和height为:$(input_size + 2\times padding_size - filter_size)/stride + 1$
一个filter可以提取一个feature,得到一个feature map,为了提取多个feature,需要使用多个filters,最后可以得到多个feature map。
所以说,feature map是一类值,因为它对应的是一个filter,给定不同的输入images,一个feature map可以有不同的取值。这个问题是我在看ZFNet中遇到的,因为它在原文中说
“For a given feature map, we show the top 9 activations”。给定一个feature map,这里应该是在所有样本中选择最大的$9$个activations对应的images。
“the strongest activation (across all training examples) within a given feature map”。给定一个feature map,在所有样本中选择一个最强的activation。
activate function
一般使用非线性激活函数relu对feature map进行变化
pooling
maxpooling
它基本上采用一个filter和一个同样长度的stride通常是(2,2)和2,然后把它应用到输入中,输出filter卷积计算的每个区域中的最大数字,这个pooling是在各个维度上分别进行的。
比如一个 22422464的input,经过一个(2,2)的maxpooling会输出一个11211232的张量
averagepooling
fc layers
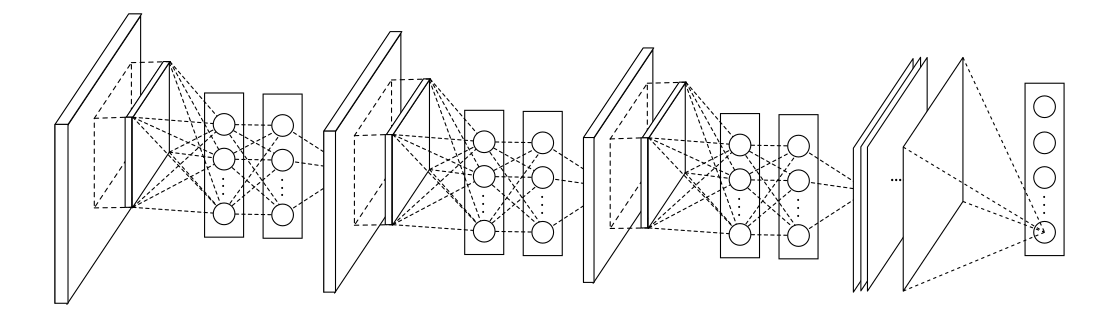
Alexnet(2012)
论文名称:ImageNet Classification with Deep Convolutional Neural Networks
论文地址:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
概述
作者提出了一个卷积神经网络架构对Imagenet中$1000$类中的$120$万张图片进行分类。网络架构包含$5$个卷积层,$3$个全连接层,和一个$1000$-way的softmax层,整个网络共有$6000$万参数,$65000$个神经元。作者提出了一些方法提高性能和减少训练的时间,并且介绍了一些防止过拟合的技巧。最后在imagenet测试集上,跑出$37.5%$的top-1 error以及$17.0%$的top-5 error。
本文主要的contribution:
- 给出了一个benchmark-Imagenet
- 提出了一个CNN架构
- ReLU激活函数
- dropout的使用
- 数据增强,四个角落和中心的crop以及对应的horizontial 翻转。
问题
1.数据集太小,都是数以万计的,需要更大的数据集。
创新
ReLU非线性激活函数
作用
作者说实验表明ReLU可以加速训练过程。
saturating nonlinearity
一个饱和的激活函数会将输出挤压到一个区间内。
A saturating activation function squeezes the input.
定义
f是non-saturating 当且仅当$|lim_{z\rightarrow -\infty} f(z)| \rightarrow + \infty$或者$|lim_{z\rightarrow +\infty} f(z)| \rightarrow + \infty$
f是saturating 当且仅当f不是non-saturating
例子
ReLU就是non-saturating nonlinearity的激活函数,因为$f(x) = max(0, x)$,如下图所示。
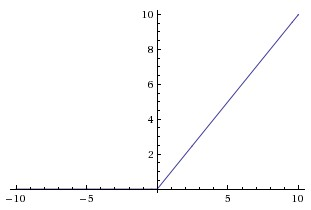
当$x$趋于无穷时,$f(x)$也趋于无穷。
sigmod和tanh是saturating nonlinearity激活函数,如下图所示。
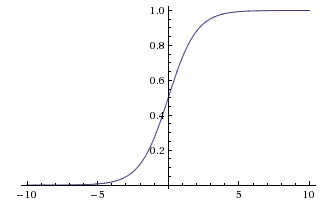
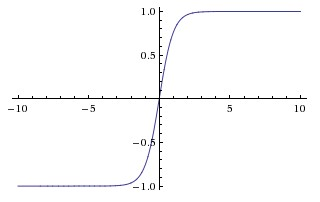
多块GPU并行
作者使用了两块GPU一块运行,每个GPU中的参数个数是一样的,在一些特定层中,两个GPU中的参数信息可以进行通信。
Overlapping Pooling
就是Pooling kernel的size要比stride大。比如一个$12\times 12$的图片,用$5\times 5$的pooling kernel,步长为$3$,步长要比kernel核小,即$3$比$5$小。
为什么这能减小过拟合?
- 可能是减小了Pooling过程中信息的丢失。
If the pooling regions do not overlap, the pooling regions are disjointed and if that is the case, more information is lost in each pooling layer. If some overlap is allowed the pooling regions overlap with some degree and less spatial information is lost in each layer.[4]
数据增强
目的:防止过拟合
裁剪和翻转
输入是$256\times 256 \times 3$的图像。
训练:对每张图片都提取多个$224\times 224$大小的patch,这样子总共就多产生了$(256-224)\times (256-224) = 1024$个样本,然后对每个patch做一个水平翻转,就有$1024\times 2 = 2048$个样本。
测试:通过对每张图片裁剪五个(四个角落加中间)$224\times 224$的patches,并且对它们做翻转,也就是有$10$个patches,网络对十个patch的softmax层输出做平均作为预测结果。
在图片上调整RGB通道的密度
使用PCA对RGB值做主成分分析。对于每张训练图片,加上主成分,其大小正比于特征值乘上一个均值为$0$,方差为$0.1$的高斯分布产生的随机变量。对于一张图片$x,y$点处的像素值$I_{xy}=[I_{xy}^R, I_{xy}G,I_{xy}B]^T$,加上$[\bold{p_1},\bold{p_2},\bold{p_3}][\alpha_1\lambda_1,\alpha_2\lambda_2,\alpha_3\lambda_3]$,其中$[\bold{p_1},\bold{p_2},\bold{p_3}]$是特征向量,$\lambda_i$是特征值,$\alpha_i$就是前面说的随机变量。
Dropout
通过学习鲁棒的特征防止过拟合。
在训练的时候,每个隐藏单元的输出有$p$的概率被设置为$0$,在该次训练中,如果这个神经元的输出被设置为$0$,它就对loss函数没有贡献,反向传播也不会被更新。对于一层有$N$个神经单元的全连接层,总共有$2^N$种神经元的组合结果,这就相当于训练了一系列共享参数的模型。
在测试的时候,所有隐藏单元的输出都不丢弃,但是会乘上$p$的概率,相当于对一系列集成模型取平均。具体可见dropout
在该模型中,作者在三层全连接层的前两层输出上加了dropout。
局部响应归一化(Local Response Normalizaiton)
事实上,后来发现这个东西没啥用。但是这里还是给出一个公式。
$$ b^i_{x,y} = \frac{a^i_{x,y}}{(k+\alpha \sum{min(N-1,\frac{i+n}{2})}_{j=max(0,\frac{i-n}{2})}(aj_{x,y})^2)^{\beta}}$$
其中$a^i_{x,y}$是在点$(x,y)$处使用kernel $i$之后,在经过ReLU激活函数。$k,n,\alpha,\beta$是超参数。
It seems that these kinds of layers have a minimal impact and are not used any more. Basically, their role have been outplayed by other regularization techniques (such as dropout and batch normalization), better initializations and training methods.
整体架构
目标函数
多峰logistic回归。
并行框架
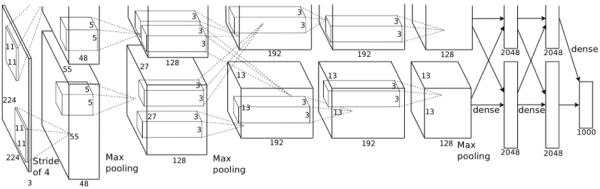
下图是并行的架构,分为两层,上面一层用一个GPU,下面一层用一个GPU,它们只在第三个卷积层有交互。
简化框架
下图是简化版的结构,不需要使用两个GPU。
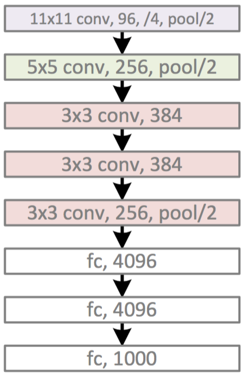
数据流(简化框架)
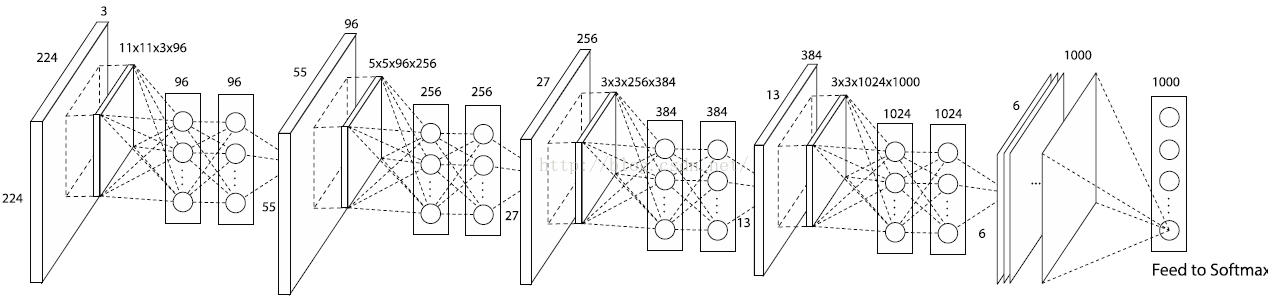
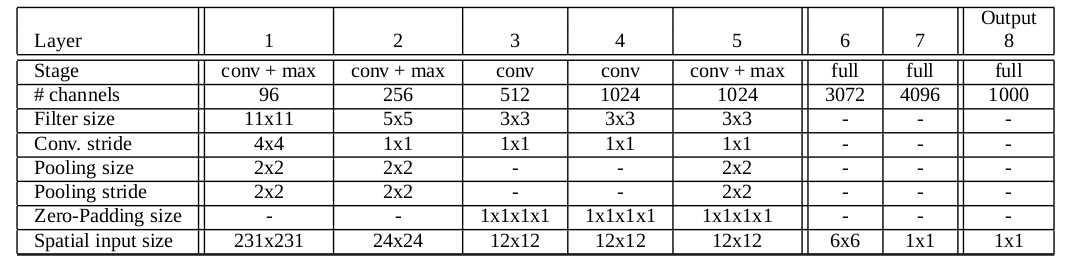
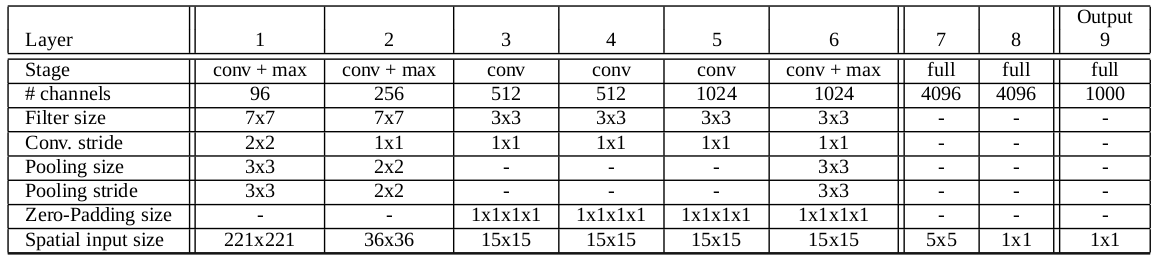
输入是$224\times 224 \times 3$的图片,第一层是$96$个stride为$4$的$11\times 11\times 3$卷积核构成的卷积层,输出经过max pooling(步长为2,kernel size为3)输入到第二层;第二层有$256$个$5\times 5\times 96$个卷积核,输出经过max pooling(步长为2,kernel size为3)输入到第三层;第三层到第四层,第四层到第五层之间没有经过pooling和normalization),第三层有384个$3\times 3\times 256$个卷积核,第四层有$384$个$3\times 3\times 384$个卷积核,第五层有$256$个$3\times 3\times 384$个卷积核。然后接了两个$2048$个神经元的全连接层和一个$1000$个神经元的全连接层。
实验
Datasets
ILSVRC-2010
Baselines
- Sparse coding
- SIFT+FV
- CNN
Metric
- top-1 error rate
- top-5 error rate
代码
pytorch实现
https://github.com/mxxhcm/myown_code/blob/master/CNN/alexnet.py
Maxout networks
论文名称:Maxout Networks
下载地址:https://arxiv.org/pdf/1302.4389.pdf
NIN
论文名称:Network In Network
论文地址:https://arxiv.org/pdf/1312.4400.pdf
摘要
这篇文章作者使用更复杂的micro神经网络代替CNN,用一个mlp实例化micro nn。CNN中的filter用的是generalized linear model(GLM)。本文使用nonlinear的FA,作者用一个multi layers perceptron 取代GLM。通过和cnn类似的操作对input进行sliding得到feature maps,然后传入下一层,deep NIN通过堆叠多层类似的结构生成。同时作者使用average pooling取代最后的fullcy connected layer。
本文的两个contribution是:
- 使用MLP代替CNN中linear model,引入$1\times 1$的filter
- 使用average pooling代替fully connected layer。
在传统的CNN中,一个concept的不同variation可能需要多个filters,这样子会让下一层的的计算量太大。高层CNN的filters对应input的区域更大,高层的concept是通过对底层的concepts进行组合得到的。这里作者在每一层都对local patch进行组合,而不是在高层才开始进行组合,在每一层中,micro network计算更加local patches更abstract的特征。
Network in Network
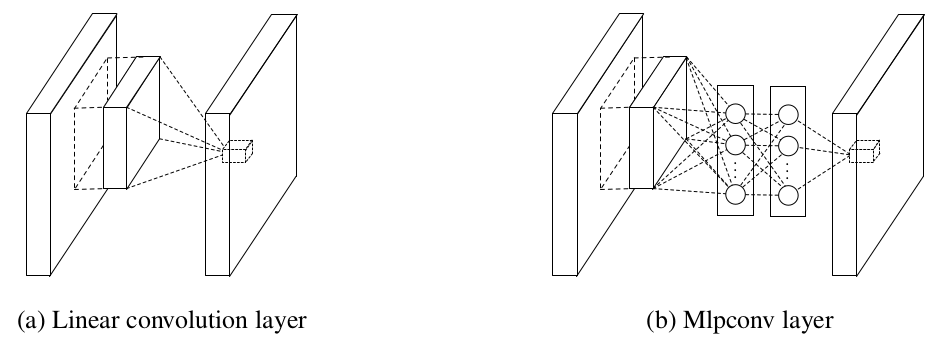
MLP convolution layers
为什么使用MLP代替GLP?
- MLP和CNN的结构兼容,可以使用BP进行训练;
- MLP本身就是一个deep model,满足feature复用的想法。
如下图所示,是MLP CNN和GLP CNN的区别。
MLP的公式如下。
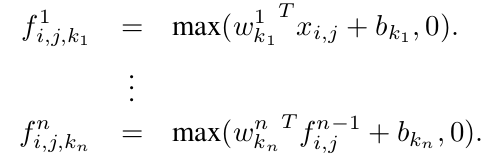
从cross channel(feature maps)的pooling角度来看,上面的公式相当于在一个正常的conv layer上进行多次的parametric pooling,每一个pooling layer对输入的feature map进行线性加权,经过一个relu层之后在下一层继续进行pooling。Cross channel pooled的feature maps在接下来的层中多次进行cross channel pooling。这个cross channel pooling的结构的作用是学习复杂的cross channel信息。
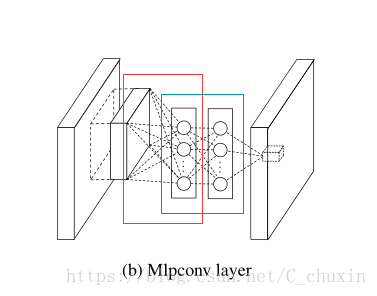
其实整个cross channel的paramteric pooling结构相当于一个普通的卷积加上了多个$1\times 1$的卷积,如下图所示:
Global average pooling
FC layers证明是容易过拟合的,dropout被提出来正则化fc layers的参数。
本文提出的global average pooling取代了CNN的fc layers,直接在最后一个mlpconv layer中对应于分类任务中的每个类别生成一个feature map。然后用在feature maps上的average pooling代替fc layers,然后把它送入softmax layer。原来的CNN是将feature map reshape成一个一维向量,现在是对每一个feature map进行一个average pooling,有多少个feature map就有多少个pooling,相当于一个feature map对应与一个类型。
这样做有以下几个好处:
- 在fc layers上的global average pooling让feature map和categories对应起来,feature map可以看成类别的置信度。
- 直接进行average pooling不用优化fc layer的参数,也就没有过拟合问题。
- global average pooling对全局信息进行了加和,对于input的spatial信息更加鲁邦。
NIN
如下图所示,是NIN的整体架构。
下图是一个具体参数化的示例
实验
OverFeat(2013)
论文名称:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
论文地址:https://arxiv.org/pdf/1312.6229.pdf
概述
本文提出了一个可用于classification, localization和detection等任务的CNN框架。
ImageNet数据集中大部分选择的是几乎填满了整个image中心的object,image中我们感兴趣的objects的大小和位置也可能变化很大。为了解决这个问题,作者提出了三个方法:
- 用sliding window和multiple scales在image的多个位置apply ConvNet。即使这样,许多window中可能包含能够完美识别object类型的一部分,比如一个狗头。。。最后的结果是classfication很好,但是localization和detection结果很差。
- 训练一个网络不仅仅预测每一个window的category distribution,还预测包含object的bounding box相对于window的位置和大小。
- 在每个位置和大小累加每个category的evidence
Vision任务
classification,localization和detection。classification和localization通常只有一个很大的object,而detection需要找到很多很小的objects。
classification任务中,每个image都有一个label对应image中主要的object的类型。为了找到正确的label,每个图片可以猜$5$次(图片中可能包含了没有label的数据)。localization任务中,不仅要给出label,还需要找到这个label对应的bouding box,bounding box和groundtruth至少要有$50$匹配,label和bounding box也需要匹配。detection和localization不同的是,detection任务中可以有任何数量的objects,false positive会使用mean average precison measure。localization任务可以看成classification到detection任务的一个中间步。
FCN
用卷积层代替全连接层。具体是什么意思呢。
alexnet中,有5层卷积层,3层全连接层。假设第五层的输出是$5\times 5 \times 512$,$512$是output channels number,$5\times 5$是第五层的feature maps的大小。如果使用全连接的话,假设第六层的输出单元是$N$个,第六层权重总共是$(5\times 5\times 512) * (N)$,对于一个训练好的网络,图片的输入大小是固定的,因为第六层是一个全连接层,输入的大小是需要固定的。如果输入一个其他大小的图片,网络就会出错,所以就有了Fully Convolutional networks,它可以处理不同大小的输入图片。
如下所示,使用某个大小的image训练的网络,在classifier处用卷积层替换全连接层,如果使用全连接层,首先将$(5, 5, out_channels)$的feature map进行flatten $5\times 5\times out_channels$,然后经过三层全连接,最后输出一个softmax的结果。而fcn使用卷积层代替全连接,使用$N$个$5\times 5$的卷积核,直接得到$1\tims 1 \times N$的结果,最后得到一个$1\times 1\times C$的输出,$C$代表图像类别,$N$代表全连接层中隐藏节点的数量。
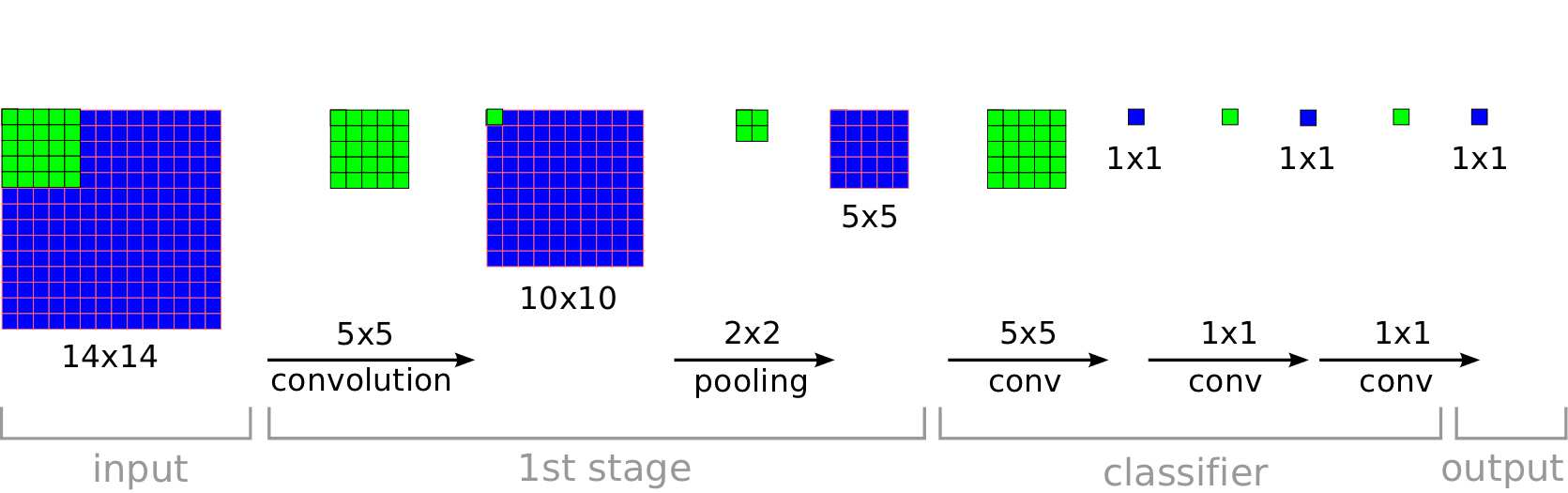
事实上,FCN和全连接的本质上都是一样的,只不过一个进行了flatten,一个直接对feature map进行操作,直接对feature map操作可以处理不同大小的输入,而flatten不行。
当输入图片大小发生变化时,输出大小也会改变,但是网络并不会出错,如下所示:
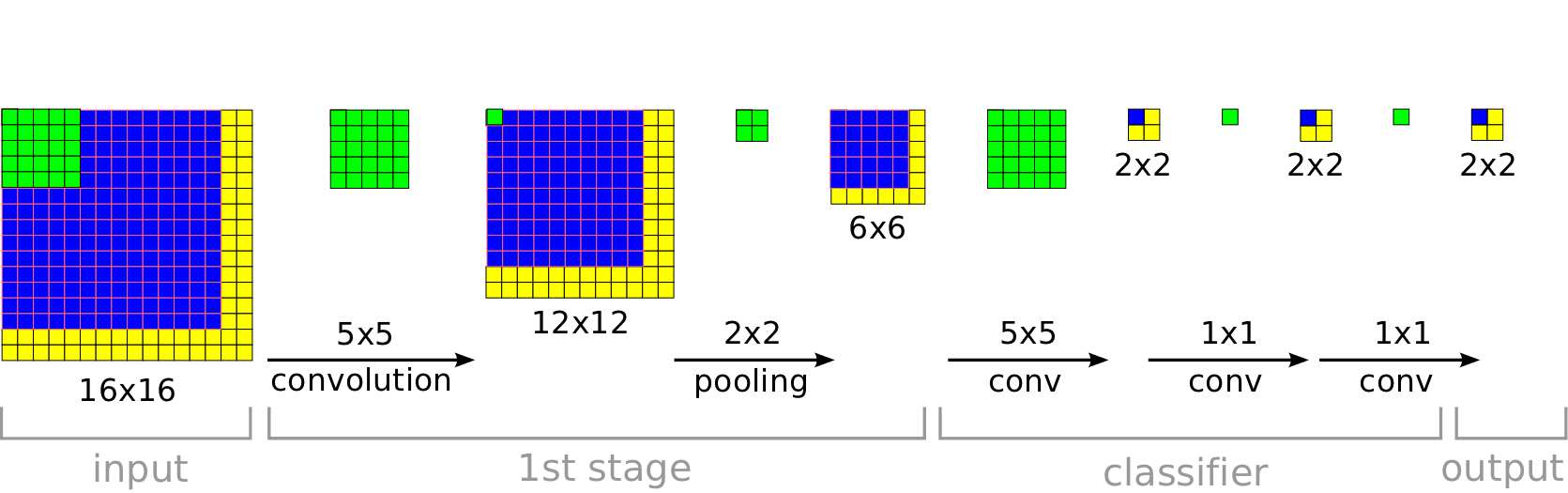
最后输出的结果是$2\times 2 \times C$的结果,可以直接对它们取平均,最后得到一个$1\times 1\times C$的分类结果。
offset Max pooling
我们之前做max pooling的时候,设$kernel_size=3, stride_size=1$,如果feature map是$3$的倍数,那么只有一个pooling的结果,但是如果不是$3$的倍数,max pooling会很多个结果,比如有个$20\times 20$的feature map,在$x,y$上做max pooling分别有三种结果,分别从$x,y$的位置$0$开始,位置$1$开始,位置$2$开始,排列组合有$9$中情况,这九种情况的结果是不同的。
如下图所示,在一维的长为$20$的pixels上做maxpooling,有三种情况。
overfeat
这两个方法中,fcn是在输入图片上进行的window sliding,而offset maxpooling是在feature map进行的window sliding,这两个方法结合起来就是overfeat,要比alexnet直接在输入图片上进行window sliding 要好。
Classification
training
- datset
Image 2012 trainign set(1.2million iamges,C=$1000$ classes)。 - data argumented
对每张图片进行下采样,所以每个图片最小的dimension需要是$256$。
提取$5$个random crops以及horizaontal flips,总共$10$个$221\times 221$的图片 - batchsize
$128$ - 初始权重
$(\mu, \sigma)= (0, 1\times 10^{-2})$ - momentum
0.6 - l2 weigth decay
$1\times 10^{-5}$ - lr
初始是$5\times 10^{-2}$,在$(30,50,60,70,80)$个epoches后,乘以$0.5$ - non-spatial
这个说的是什么呢,在test的时候,会输出多个output maps,对他们的结果做平均,而在training的时候,output maps是$1\times 1$。
model架构
下图展示的是fast model,spatial input size在train和test时候是不同的,这里展示的是train时的spatial seize。layer 5是最上层的CNN,receptive filed最大。后续是FC layers,在test时候使用了sliding window。在spatial设置中,FC-layers替换成了$1\times 1$的卷积。
下图给出了accuracy model的结构,
总的来说,这两个模型都在alexnet上做了一些修改,但是整体架构没有大的创新。
多scale classification
alexnet中,对一张照片的$10$个views(中间,四个角和horizontal flip)的结果做了平均,这种方式可能会忽略很多趋于,同时如果不同的views有重叠的话,计算很redundant。此外,alexnet中只使用了一个scale。
作者对每个iamge的每一个location和多个scale都进行计算。
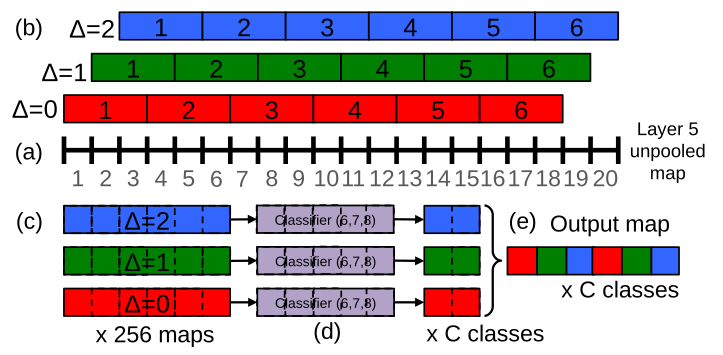
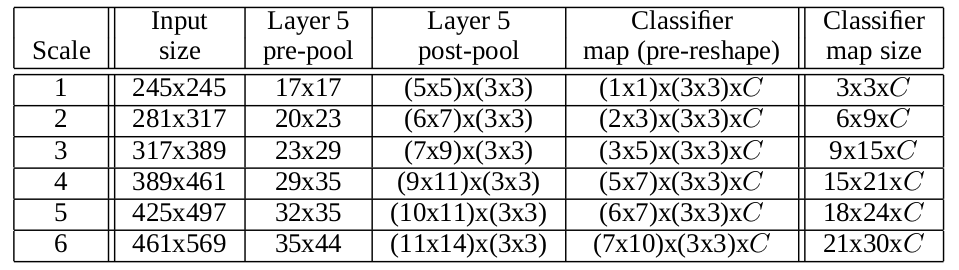
如下图,对应了不同大小的输入图片,layer 5 post pool中$(m\times n)\time(3\times 3)$,前面$m\times n$是fcn得到的不同位置的feature map,后面$3\times 3$是$kernel_size=3$的offset max pooling得到的featrue map。乘起来是所有的预测结果。
localization
Detection
ZFNet(2014)
论文名称:Visualizing and Understanding Convolutional Networks
论文地址:https://cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
为什么叫ZFNet,两个作者名字首字母的拼写。
首先我有一个问题?就是什么是一个activation。在原文的$2.1$节,有这样一个介绍:
We present a novel way to map these activities back to the input pixel space, showing what input pattern originally caused a given activation in the feature maps.
我的理解是一个activation就是feature map中的一个unit。事实上,feature map也叫activation map,因为它是image中不同parts的acttivation,而叫feature map是因为它是image中找到特定的feature。
概述
这篇文章从可视化的角度给出中间特征的和classifier的特点,分析如何改进alexnet来提高imagenet classification的accuracy。
为什么CNN结果这么好?
- training set越来越大
- GPU的性能越来越好
- Dropout等正则化技术
但是CNN还是一个黑盒子,我们不知道它为什么表现这么好?这篇文章给出了一个可视化方法可视化任意层的feature。
那么本文的contribution是什么呢?使用deconvnet进行可视化,通过分析特征行为,对alexnet进行fine tune提升模型性能。
使用deconvnet可视化
什么是deconvnet?可以看成和convnet拥有同样组成部分(pooling, filter)等,但是是反过来进行的。如下图所示,convnet是把pixels映射到feature,或者到底层features映射到高层features,而deconvnet是把高层features映射到底层features,或者把features映射到pixels。在测试convnet中给定feature maps的一个activation时,设置所有其他的activation为0,将这个feature map传入deconvnet网络中。
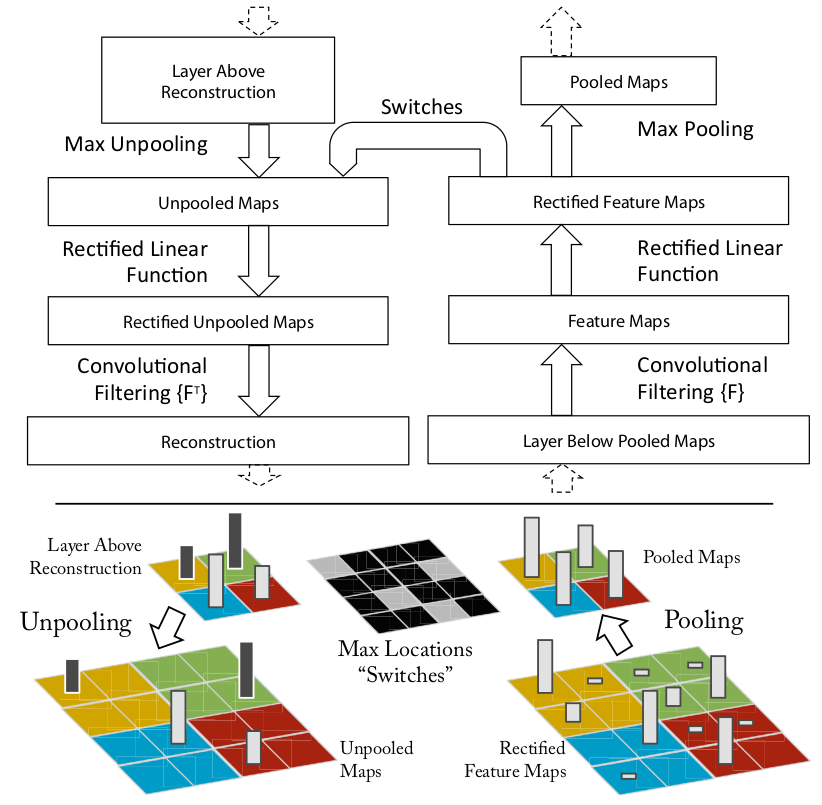
图片左上为deconv,右上为conv。conv的流程为filter->rectify->pooling;deconv的流程为unpool->rectify->filter。
Unpooling
convnet中的max pooling是不可逆的,这里作者使用switch variables记录下max pooling后的元素在没有pooling时的位置,进行近似的恢复。
Rectification
convnet使用relu non-linearities。deconvnet还是使用relu,这里我有些不理解,为什么?为什么deconve还是使用relu
Filtering
deconvnet使用convnet中filters的transposed版本。
Training
整体架构
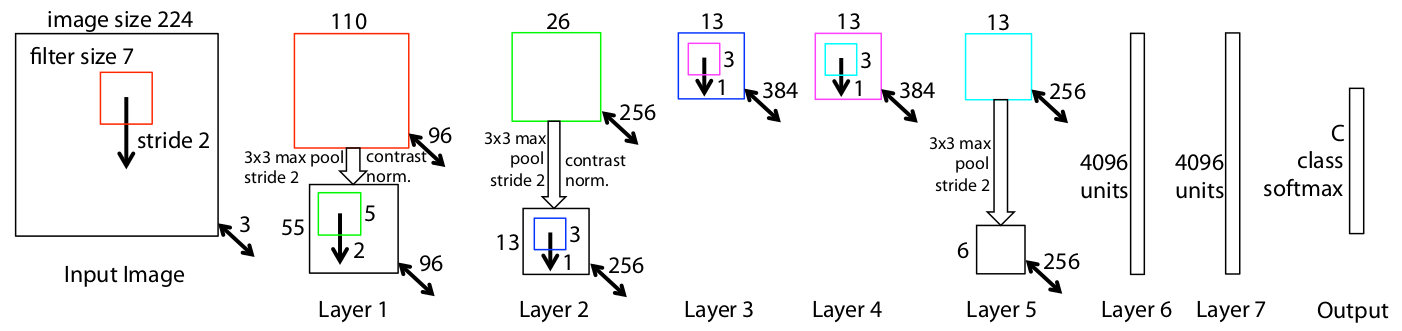
- training set
1.3百万张图片,1000类 - processed
每个RGB图像resized成最小边维度为$256$,cropping中间的$256 \times 256$,减去所有像素的平均值。crops$10$个$224\times 224$(四个角落和中心以及horizontal flips) - 优化方法
带momentumSGD - batch size
128 - lr
初始是$10^{-2}$,然后手动anneal - momentum
0;9 - Dropout
layer 6和layer 7,0.5 - weights和biases初始化
weights设置为$10^{-2}$,biases设置为$0$ - normalizaiton
对第一层的filter,如果RMS超过了$10^{-1}$就设置为$10^{-1}$ - 训练次数
70epochs
Visualizaiton
Feature visualization
如下图所示,使用deconvnet可视化一些feacutre activation。给定一个feature map,选择其中最大的$9$个activations对应的样本,一个feature map是通过一个filter得到的,而一个filter提取的是一个特征,所以这$9$个activations都是一个filter提取的不同图片中的同一个特征。然后将它们输入deconvnet,得到pixel spaces,可以查看哪些不同的结构(哪些原始)产生了这个feature,展现这个filter对于输入deformation的invariance。在黑白图像的旁边有对应的图像原图,他们要比feature的variation更多,因为feature关注的是图像的invariance。比如layer 5的第一行第二列的九个图,这几个patch看起来差异很大,但是却在同一个feature map中,因为这个feature map关注的是背景中的草,并不是其他objects。更多的我们可以看出来,第二层对应corner和edge等,第三次对应更复杂的invariances,比如textures和text等。第四层更class-specific,第五层是object variation。

Feature evolution durign training
下图随机选择了几个不同的feature,然后展示了他们在不同layer不同epochs(1, 2, 5, 10, 20, 30, 40, 64)的可视化结果。

架构选择
通过可视化alexnet的first layer和second layer,有了各种各样的问题。First layer中主要是high和low frequency的信息,而2nd layer有很多重复的,因为使用stride为$4$而不是$2$。作者做了两个改进:
- 将first layer的filter size从$11\times 11$改成了$7\times 7$
- 卷积的步长从$4$改成了$2$
如下图所示:

Occlusion Sensitivity
model是否真的识别了object在image中的位置,还是仅仅使用了上下文信息?下图中的例子证明了model真的locate了object,当遮挡住物体的部分增大时,给出正确分类的概率就减小了。移动遮挡方块的位置,给出一个和方块位置相关的分类概率函数,我们可以看出来,model really works。
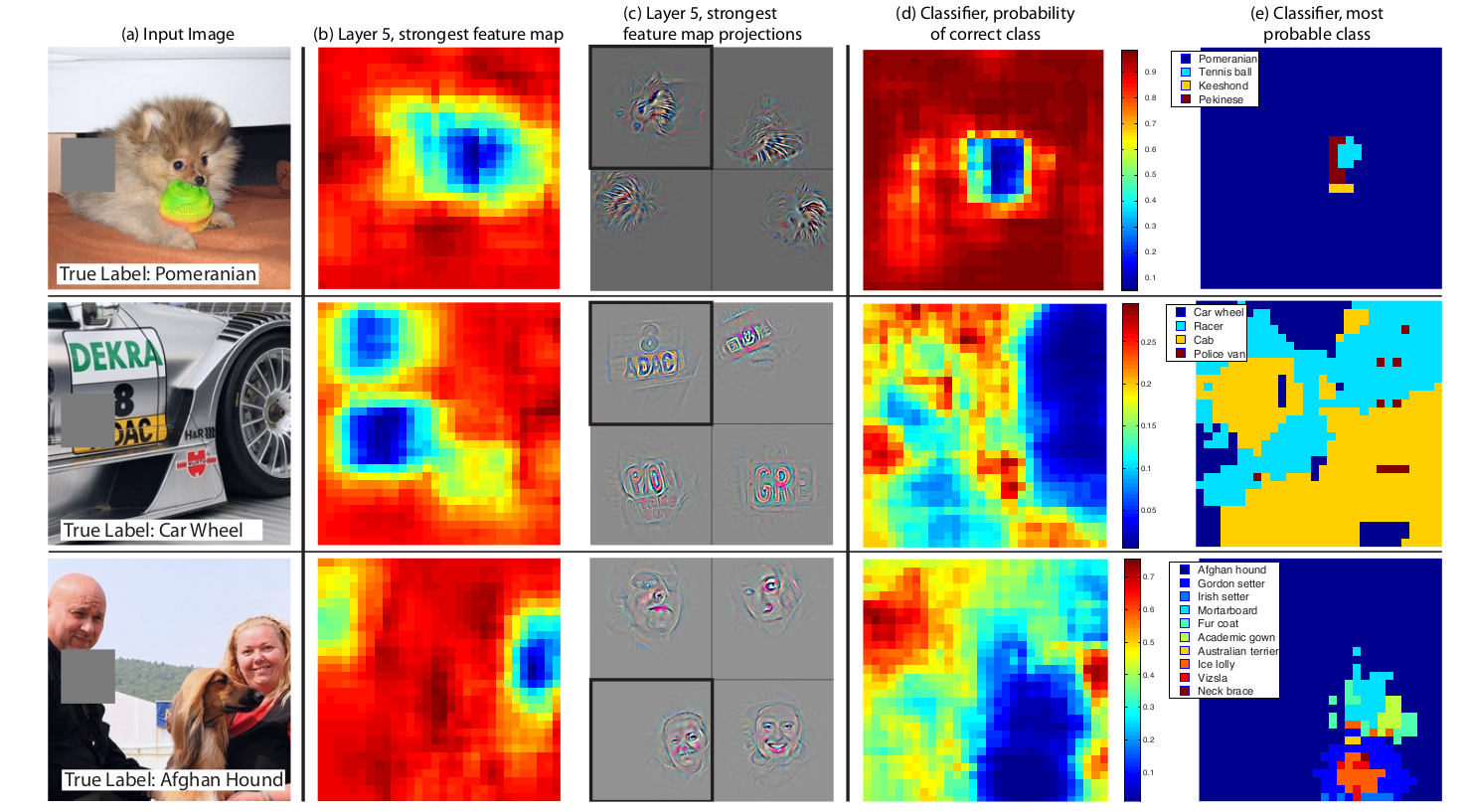
实验
第一个实验通过使用,证明了前面的特征提取层和fc layers都是有用的。
第二个实验保留前面的特征提取层和fc layers,将最后的softmax替换。
VGGNet(2014)
论文名称:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
论文地址:https://arxiv.org/pdf/1409.1556.pdf http://arxiv.org/abs/1409.1556.pdf
VGG是Visual Geometry Group的缩写
概述
这篇文章主要研究了CNN深度对大规模图像识别问题精度的影响。本文的主要contribution就是使用多层的$3\times 3$ filters替换大的filter,增加网络深度,提高识别精度。
方案
架构
训练,输入$224\times 224$大小的RGB图片。对每张图片减去训练集上所有图片RGB 像素的均值。预处理后的图片被输入多层CNN中,CNN的filter是$3\times 3$的,作何也试了$1\times 1$的filter,相当于对输入做了一个线性变换,紧跟着一个non-linear 激活函数,这里的$1\times 1$的filter没有用于dimention reduction。stride设为$1$,添加padding使得卷积后的输出大小不变。同时使用了$5$个max-pooling层(并不是每一层cnn后面都有max-pooling),max-pooling的window是$2\times 2$,stride是$2$。
在训练的时候CNN后面接的是三个FC layers,前两个是$4096$单元,最后一层是$1000$个单元的softmax。所有隐藏层都使用ReLu非线性激活函数。
在测试的时候使用fcn而不是直接flatten。
配置
这篇文章给出了五个网络架构,用$A-E$表示,它们只有在深度上有所不同:从$11$层($8$个conv layers和$3$个FC layers)到$19$层($16$个conv layers和$3$个FC layers)。Conv layers的channels很小,从第一层的$64$,每过一个max pooling layers,变成原理啊的两倍,直到$512$。具体如下表所示。
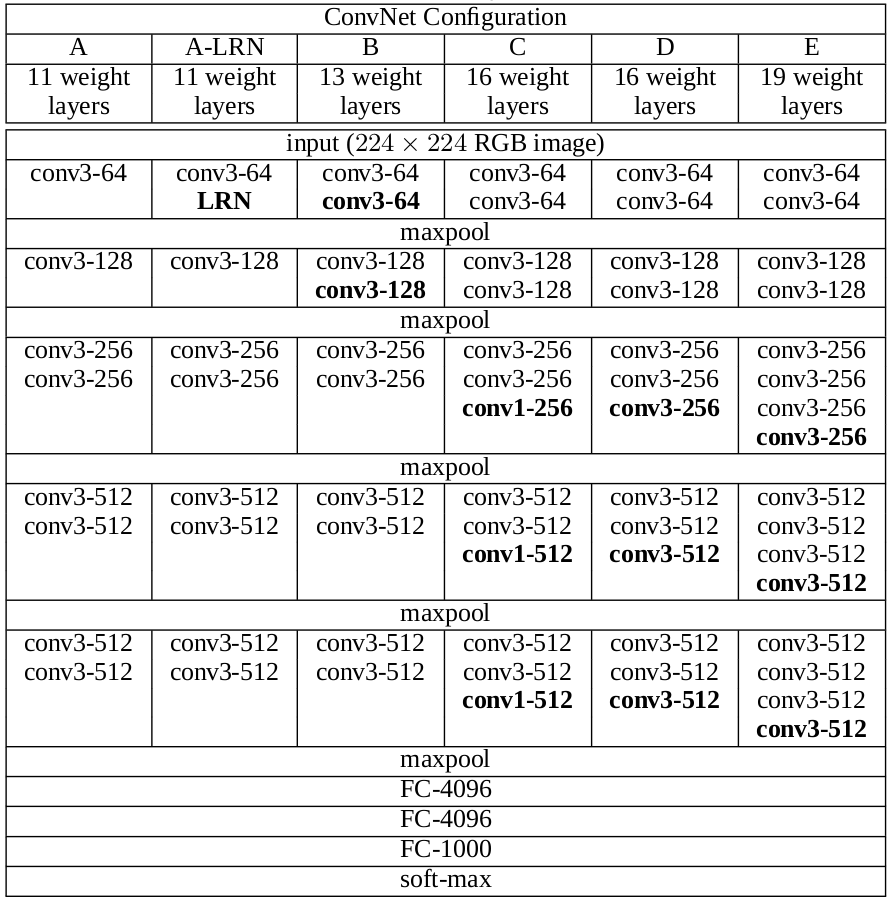
网络的参数个数如下表所示。

网络$A$的参数计算:
\begin{align*}
64\times 3\times 3\times 3 + \\
128\times 3\times 3\times 64 + \\
256\times 3\times 3\times 128 + \\
256\times 3\times 3\times 256 + \\
512\times 3\times 3\times 256 + \\
512\times 3\times 3\times 512 + \\
2\times 512\times 3\times 3\times 512 + \\
7\times 7\times 512\times 4096 + \\
4096\times 4096 + \\
4096\times 1000 = \\
132851392
\end{align*}
网络$B$的参数计算:
\begin{align*}
64\times 3\times 3\times 3 + \\
128\times 3\times 3\times 64 + \\
128\times 3\times 3\times 128 + \\
256\times 3\times 3\times 128 + \\
256\times 3\times 3\times 256 + \\
256\times 3\times 3\times 256 + \\
512\times 3\times 3\times 256 + \\
512\times 3\times 3\times 512 + \\
2\times 512\times 3\times 3\times 512 + \\
7\times 7\times 512\times 4096 + \\
4096\times 4096 + \\
4096\times 1000 = \\
133588672
\end{align*}
其实主要的网络参数还是在全连接层,$7\times 7\times 512\times 4096=102760448
$。
卷积核作用
- 为什么要用三个$3\times 3$的conv layers替换$7\times 7$个conv layers?
- 使用三个激活函数而不是一个,让整个决策更discriminative。
- 减少了网络参数,三个有$C$个通道的$3\times 3$conv layers,总的参数是$3\tims(32C2)=27C^2$,而一个$C$通道的$7\times 7$ conv layers,总参数是$49C^2$。可以看成是一种正则化。
- $1\times 1$ conv layers用来增加非线性程度,本文中使用的$1\times 1$的conv layers可以看成加了非线性激活函数的投影。
分类框架
training
- 目标函数
多峰logistic regression - 训练方法
mini-batch gradient descent with momentum - batch size
256 - momentum
0.9 - 正则化
$L_2$参数正则化(5\codt 10^{-4})
0.5 dorpout 用于前两个FC layers - lr
初始值为$10^{-2}$,当验证集的accuracy不再提升时,除以$10$。学习率总共降了$3$次,$370K$次迭代后停止。 - 图像预处理
从rescaled中随机cropped $224\times 224$的RGB图像。
使用alexnet中的随机horizontal flipping和随机RGB colour shift。 - iamge rescale
用$S$表示training image的小边的大小,$S$也叫作train sacle。网络的输入是从training image中cropped得到的$224\times 224$的图像。所以只要$S$取任何不小于$224$的值即可,如果$S=224$,那么crop在统计上会captuer整个图片,完全包含training image最小的那边;$S>>224$的时候,crop会产生很小一部分的图像。
作者尝试了固定$S$和不固定的$S$。对于固定$S$,设置$S=256$和$S=384$,首先在$S=256$上训练,然后用$S=256$训练的参数初始化$S=384$的参数,使用更小的初始学习率$10^{-3}$。不固定$S$时,$S$从$[S_{min}, S_{max}](S_{max}=512,S_{min}=256)$任意采样,然后crop。 - VGG vs alexnet
VGG参数多,深度深,但是收敛快,原因:
- 更小的filter带来的implicit regularisation
- 某些层的预先初始化。
这个解决的是网络深度过深,某些初值使得网络不稳定的问题。解决方法:先随机初始化不是很深的网络A,进行训练。在训练更深网络的时候,使用A网络的值初始化前$4$个卷基层和最后三个FC layers。随机初始化的网络参数,从均值为$0$,方差为$10^{-2}$的高斯分布中采样得到。
testing
- 测试的时候先把input image的窄边缩放到$Q$,$Q$也叫test scale,$Q$和$S$不一定需要相等。
- 这里和overfeat模型一样,在卷积网络之后采用了fcn,而不是fc layers。
classfication
ILSVRC-2012,training($1.3M$张图片),validation($50K张$),testing($100K$张)
两个metrics:top-1和top-5 error。top-1 error是multi-class classification error,不正确分类图像占的比例;top-5 error是预测的top-5都不是ground-truth。
single scale evaluation
$S$固定时,设置test image size $Q=S=256$;
$S$抖动时,设置test image size $Q=0.5(S_{min}+S_{max})=0.5(256+512)=384$,$S\in [S_{min},S_{max}]$。
multi scale evaluation
用同一个模型对不同rescaled大小的图片多次test,即对于不同的$Q$。
固定$S$时,在三个不同大小的test image size $Q={S-32,S,S+32}$评估。
$S$抖动时,模型是在$S\in [S_{min},S_{max}]$上训练的,在$Q={S_{min}, 0.5(S_{min}+S_{max}), S_{max}}$上进行test。
多个crop evaluation
这个是为了和alexnet做对比,alexnet网络在testing时,对每一张图片都进行多次cropped,对testing的结果做平均。
convnet funsion
之前作者的evaluation都是在单个的网络上进行的,作者还试了将不同网络的softmax输出做了平均。
Inception V1(GoogleLeNet)
摘要
提出一种方法能够在不增加太多计算代价的同时增加网络的深度和宽度。
motivation
直接增加网络的深度和宽度有两个缺点:
- 参数更多,容易过拟合,尤其是训练集太小的情况下,高质量的训练集很难生成。
- 需要更多的计算资源。比如两层CNN,即使每一层中线性增加filters的个数也会造成计算代价指数级增加。如果增加的权重接近$0$的话,计算代价就浪费了。而现实中的计算资源是有限的。
如何解决这个问题呢?使用sparsity layers取代fully connetcted layers。但是现在的计算资源在处理non-uniform 的sparse data时是非常低效的,即使数值操作减小$100$倍,查找的时间也是很多的。而针对CPU和GPU的dense matrix计算能够加快fc layer的学习。现在绝大部分的机器学习视觉模型在sparsity spatial domain都仅仅利用了CNN,而convolution是和前一层patches的dense connection。1998年的convnet为了打破网络对称性,改善学习结果,使用的是random和sparse连接,而在alexnet中为了并行优化计算,使用了全连接。当前cv的state-of-the-art架构使用的都是unifrom structure,为了高效的进行dense计算,filters和batch size的数量都是很大的。
稀疏性可以解决过拟合和资源消耗过多的问题,而稠密连接可以提高计算效率。所以接下来要做的是一个折中,利用filter维度的稀疏结构,同时利用硬件在dense matrices上的计算进行加速。
Inception架构就是使用一个dense组件去逼近sparse结构的例子。
算法
Inception的idea是使用dense组件近似卷积的局部稀疏结构。本文的旋转不变型是利用convolutional building blocks完成的,找到optimal local construction,然后不断堆叠。文章[11]中建议layer-by-layer的构建,分析上一层之间的关系,并将具有高相关性的units进行分组。这些相关的units cluster构建成了下一层的units,并且和上一层的units相连接。假设之前层中的每一个unit都对应输入图片中的一些region,这些units分组构成filter banks。这就意味着在靠近输入的层中我们会得到很多关于local regions相关的units。通过在下一层中使用$1\times 1$的卷积,可以找到关注于同一个region的很多个clusters。(这里加一些我自己的理解,$1\times 1$的卷积层可以找到那些重复的feature map??)当然,也有可能有更大的cluster可以通过在更大的patches上进行卷积得到,所以这里同时在一层中同时使用$1\times 1, 3\times 3, 5\times 5$的filters,使用这些大小的filter仅仅是因为方便,然后将他们的输出进行组合当做下一层的输入。当然可以加上pooling,如下图所示。
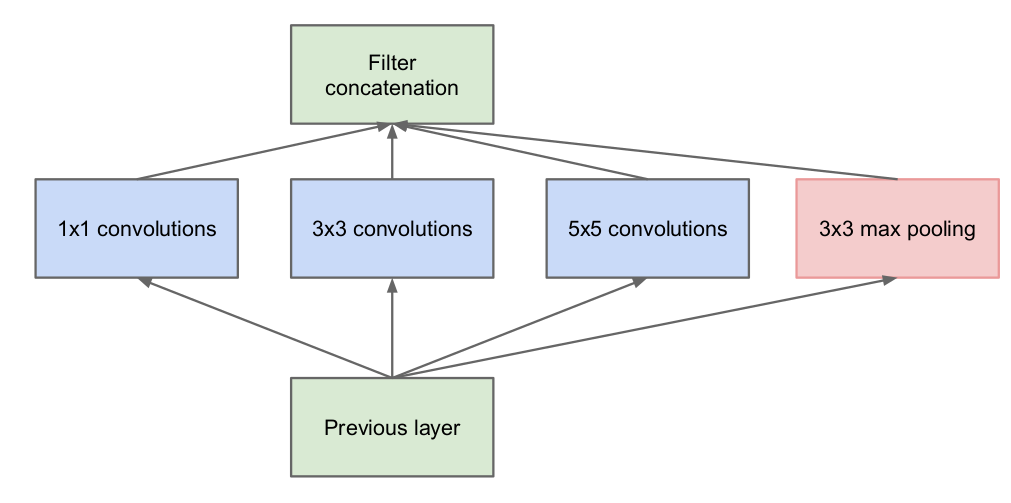
但是,这样子计算量还是很大,大量$3 \times 3, 5\times 5$在卷积时的计算量,如果再加上输入shape和输出shape相等的max pooling操作,下一层的输入维度相当大,计算开销j就爆炸了。这就使用了本文的第二个idea:使用$1\times 1$的filter降维减少计算量。在$3\times 3, 5\times 5$大小filter之前添加$1\times 1$的卷积进行降维。
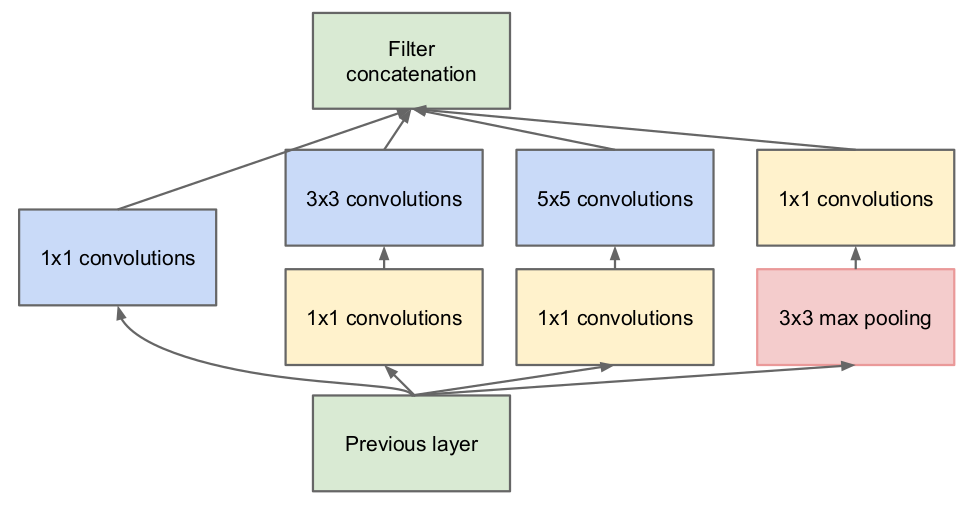
这个架构的好处:
- 在每一层都可以增加units的数量而不用担心计算量暴增。首先将上一层大量filters的输出进行进行降维,然后输入到下一层。
- visual信息用不同的scales进行处理,然后拼接起来,这样子在下一层可以同时从不同scales中提出features。
GoogLeNet
作者给出了Inception的一个示例,叫GoogLeNet。网络具体配置如下:
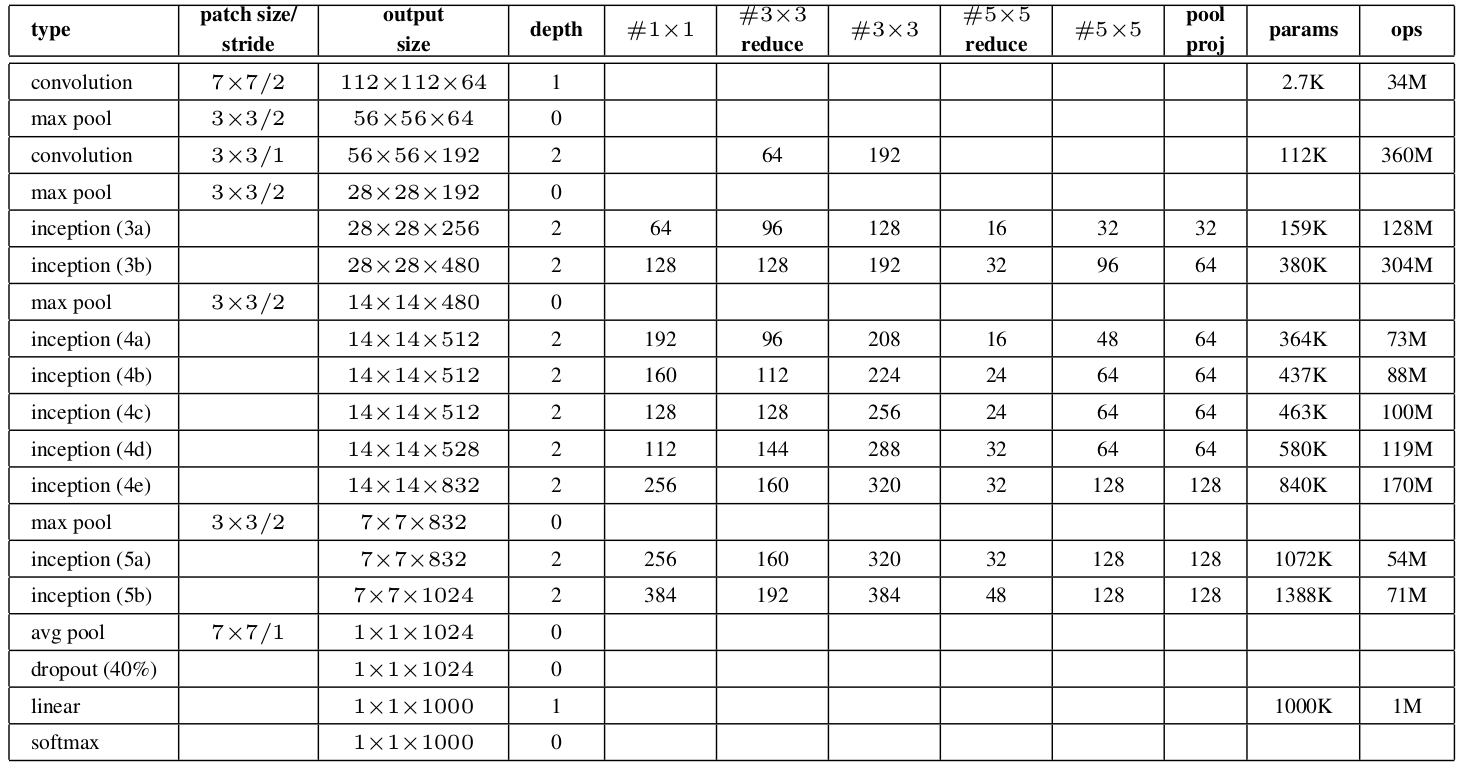
其中,"#$3 \times 3$ reduce"和"#$5 \times 5$ reduce"表示在$3\times 3, 5\times 5$卷积之前使用$1\times 1$的filters个数,pool proj这一列表示在max pooling之后的$1\times 1$的filters个数。
作者在GoogLeNet中还使用了两个额外的分类层辅助训练。通过观察得知相对shallower的网络有很好的性能,那么在反向传播时,深层网络的中间特征应该是很有判别力的。
通过在网络中间添加辅助的classfiers,作者想要让网络底层也有判别力。在训练的时候,在$4a$和$4d$模块后添加分类器,然后将所有的loss乘上一个权重加到总的loss上,在test时,这些辅助网络被扔掉。
Batch Normalization
论文名称:Batch Normalization: Accelerating Deep Network Training b
y Reducing Internal Covariate Shift
论文地址:https://arxiv.org/pdf/1502.03167.pdf
概述
在训练深度神经网络的时候,随着训练的不断进行,网络权重在不停的变,除了第一层之外的每层输入也在不停的变,所以就使得权重每次都要去适应新的输入distributions。这就导致训练速度很慢,学习率的要很小,很难使用saturaing nonlinearities激活函数训练。作者把这个问题叫做internal covariate shift,提出了batch normalization解决该问题,bn对于参数初始化的要求没那么高,允许使用更高的学习率。
BN可以看成一种正则化手段。
简介
SGD相对于单个样本的GD来说,使用mini-batch的梯度作为整个训练集的估计值,效果更好;同时并行计算提高了效率。之前的工作使用ReLU,更好的初始化以及小的学习率来解决梯度消失问题,而本文作者的想法是让非线性输入的分布尽可能稳定,从而解决梯度饱和等问题,加快训练。本文提出的batch normalization通过固定每一层输入的均值和方差减少internal covariate shift,同时减少了gradients对于初始参数的依赖性。在使用了BN的网络中,也可以使用如sigmod和tanh的saturating nonlirearities激活函数,并不是一定要用relu激活函数。
Mini-Batch Normalization
Whitening每一层的所有inputs需要很大的代价,而且并不是每个地方都是可导的。作者进行了两个简化。第一个是并不是对所有输入的features进行whiten,而是对每一个feautre单独的normalization,将他们转化成均值为0,方差为1的数据。对于一个d维的输入$x=(x^1,\cdots, x^d),对每一维进行normalize:
$$\hat{x}^k= \frac{x^k - \mathbb{E}\left[xk\right]}{\sqrt{Var\left[xk\right]}}$$
其中的期望和方差是整个training set 的期望和方差。但是仅仅normalize每一层的输入可能改变这一层的表示。比如normalize sigmod的输入会将它们的输出限制在非线性的线性区域。为了解决这个问题,在网络中添加的这个transformation应该能够表示identity transform,作者对每个activation $xk$引入了一对参数,$\gammak, \beta^k$,它们对normalized value进行scale和shift:
$$y^k = \gamma^k \hat{x}^k + \beta^k$$
这些参数和模型参数一块,都是学习出来的,如果学习到$\gammak=\sqrt{Var\left[xk\right]},\beta^k = \mathbb{E}\left[x^k\right]$,就可以表示恒等变换了。。
上面说的是使用整个training set的方差和期望进行normaliza,事实上,在sgd中这是不切合实际的。因此,就引入了第二个简化,使用每个mini-batch的方差和期望进行normalize,并且方差和期望是针对于每一个维度计算的。给出一个大小为$m$的batch $B$,normalization独立的应用于每一个维度。用$\hat{x}_{1,\cdots, m}$表示normalized values,以及它们的linear transformation:$y_{1,\cdots,m}$。这个transform表示为:$BN_{\gamma, \beta}:x_{1,\cdots, m} \rightarrow y_{1,\cdots,m}$,称为Batch Normalization Transform,完整的算法如下:
算法1 Batch Normalizing Transform
输入: mini-batch:$B={x_{1,\cdots, m}},要学习的参数$\gamma,\beta$
输出:${y_i=BN_{\gamma,\beta}(x_i)}$
$\mu\leftarrow \frac{1}{m}\sum_{i=1}^mx_i$ 计算batch的mean
$\sigma^2_B\leftarrow \sum_{i=1}m(x_i-\mu_B)2$ 计算batch的variance
$\hat{x}_i\leftarrow \frac{x_i-\mu_B}{\sqrt{\simga^2_B+\epsilon}}$ normalize
$y_i\leftarrow \gamma \hat{x}_i+ \beta \equiv BN_{\gamma, \beta}(x_i)$ scale以及shift。
整个过程的loss还可以通过backpropagate进行传播,即它是可导的。
Batch-Normalized CNN
原来的CNN是
$$ z= g(Wu+b)$$
现在在nonlinearity前加上BN transform。
$$ z= g(BN(Wu+b))$$
但是事实上,Wu+b和Wu的效果是一样的,因为normalized的时候会减去均值,所以最后就是:
$$ z= g(BN(Wu))$$
BN在Wu的每一个维度上单独使用BN,每一个维度有一对$\gammak,\betak$。
BN能使用更大的学习率
BN正则化模型
Residual Network(2015)
论文名称:Deep Residual Learning for Image Recognition
论文地址:https://arxiv.org/pdf/1512.03385.pdf
概述
作者提出了参差网络,容易优化,仅仅增加深度就能得到更高的accuracy。在Imagenet上使用比VGG深八倍的152层的residual网络,但是计算复杂度更低。
网络是不是越深越好?并不是!事实上,随着网络的加深,会出现退化问题-即增加网络的深度,accuracy反而会下降。导致这个问题的原因并不是过拟合,至于是什么原因?
在这篇文章中,作者提出了deep residual network。使用一些stacked non-linear layers你和一个residual mapping,而不是直接学习一个underlying mapping。用$H(x)$表示一个underlying mapping,我们的目标是学习一个residual mapping:$F(x) = H(x)-x$,underlying mapping可以写成$H(x) = F(x)+x$。在某种情况下,如果identity mapping是optimal,那么让$F(x)$接近于$0$可能比让stacked non linear layers拟合一个identity mapping要简单。。如下图所示,$H(x)$可以用下图表示,由一个feedforward nn加上shortcut connections(skip one or more layers的connection)组成:
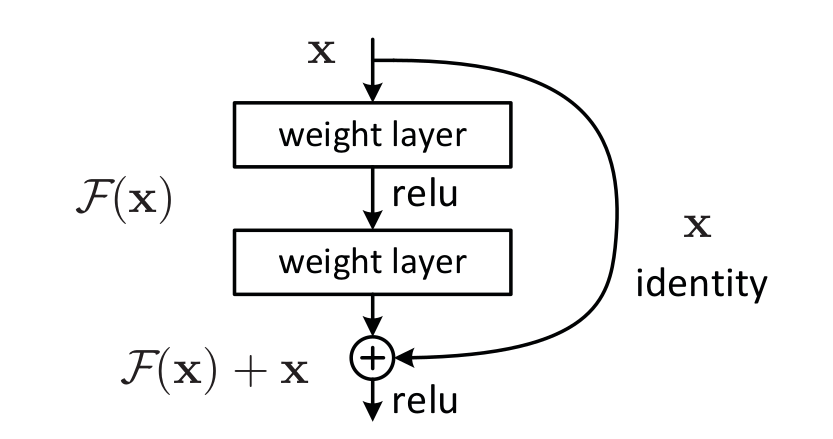
shortcut connection在这里就是一个identity mapping,不需要额外的参数和计算量,shorcut的输出和$F(x)$的输出再一块经过relu激活函数。
本文的contribution是什么?
加了一个恒等映射让深度网络的训练变得更容易。具体原理是什么?可以从这样一个角度看,在每一层都可以把不同维度的feature进行重组。residual connection是skip的一种方式??
Residual Learning
用$H(x)$表示stacked non linear layers拟合的一个underlying mapping,$x$为stacked layers的输入。原来我们用这些layers逼近一个复杂的函数,现在我们用它逼近residual function,即$F(x) = H(x) -x$(假设输入和输出的维度是一样的),原来想要拟合的函数变成了$F(x)+x$,它们的意义是一样的,但是对于learning的帮助却有很大差别。
如网络degradation问题中,如果更深的网络中添加的新layers是identity mapping,那么这个更深的网络的training error至少也要和浅一些的网络一样,然而事实上并不是这样的。在degradation问题中,说明multip nonlinear layers在近似identity mappings时效果并不是很好。而在residual learnign中,如果identity mapping是optimal,那么可以让non linear layers的权重接近于0,最后得到一个indetity mappings。虽然在real cases中,identity mapping几乎不可能是optimal的,但是如果optimal function更接近identity mapping而不是zero ampping,residual learning的效果就要更好。
Identity Mapping by Shortcuts
本文中采用的residual block如上上图所示,用公式表示为:
$$y = F(x, {W_i}) + x$$
其中$x,y$是输入和输出向量,函数$F(x, {W_i})$表示要学习的residual mapping,residual block块中有两层,$F=W_2\sigma(W_1x)$表示第一层和第二层,然后$F+x$表示shortcut connection以及element-wise addition。如果$x$和$F(x)$的维度不一样的话,可以进行一个linear projection:
$$y=F(x,{W_i}) + W_sx$$
$W_s$表示线性变换的矩阵。如果必要的话,$W_s$可以走一样线性变换,事实上,实验表明如果维度一样的话,identity mapping足够解决degradation问题,$W_s$就是用来进行dimension matting。
$F$的形式是很灵活的,可以像本文一样使用linear layers,当然也可以使用更多layers,无所谓。
网络架构
作者给出了三个网络架构,一个是VGG,一个是VGG修改得到的网络,另一个是这个修改的网络加上shortcut connection,如图所示。基于VGG的修改有以下两个原则:
- feature map的大小不变的话,filters的数量不变
- feature map的大小减半的话,filters的数量变为原来的$2$倍,保证每一层的计算复杂度不变。
网络最后接一个global average pooling layer和一个1000way的fc layer和softmax。
其他细节
- image的短边被resize到$[256, 480]$之间。然后从中裁剪一个$224 \times 224$的样本或者它的horizontal filp。
- 使用标准的颜色增强。
- 使用BN
- 从头开始训练网络
- 使用batch size为$256$的SGD
- 学习率从$0.1$开始,每到error不再改变时,除以$10$,总共进行$60\times 10^4$次迭代。
- 权重decay为$0.0001$,mementum为$0.9$。
- 测试时,对十个crop取平均,使用fcn,对多个scales上的scores进行平均。
结论
14.https://www.quora.com/How-does-deep-residual-learning-work
15.https://kharshit.github.io/blog/2018/09/07/skip-connections-and-residual-blocks
16.https://stats.stackexchange.com/questions/56950/neural-network-with-skip-layer-connections